This is the longer version of a short, informal talk I gave at SQ Collective's The Stage on May 1, 2026 - an open co-work Friday in Singapore where someone stands up at 1:30, shares something they're actively chewing on, and then everyone goes back to their laptops.
Watch the talk and Q&A in full!
If you'd rather read it than watch it, the slides are below, and I've laid the deck out inline through the rest of the post.

I run a company that sits at the bottom of the stack
My name's Hrishi. I run a company called Southbridge - small team. We make data agents: effectively, automating the process of data engineering, end to end. I didn't fully know how difficult that was when we started, but I kind of did, because it's what I'd done for the previous five or six years with much larger teams. Despite all the advancements in technology and AI, solving data problems has stayed very, very manual. It takes a human to look at information and figure out what's an outlier and what isn't, what works and what doesn't, what's intended and what's not.

So we started out building transformation systems, and today we work with companies and think tanks to build codebooks for health data, to join up SEC filings, to do large-scale database migrations, and to solve ingest. For the last six months or so, the North Star has been ingest: how do you take new data coming into a company - a new customer, a new dataset if you're doing research - and bring it into your systems with no mistakes.
Here's the thing that's been quietly working against us the whole time. Over the last year or so, models have gone from junior-dev, junior-intern to "oh, you're so smart, I don't even know how you work here" levels of smart. But the amount of information they can see at once has not gone up. If anything, it's gone down. Gemini was the top of the frontier at 2 million tokens, then it came back down to 1 million.... That's maybe 2 megabytes of data. So at any point in time - whether you're using Cursor, or some complicated thing, or our thing - the model on the other side is only ever seeing about a megabyte of data, and I'm being generous. Past a megabyte it starts degrading. Maybe past 500 kilobytes it starts degrading....
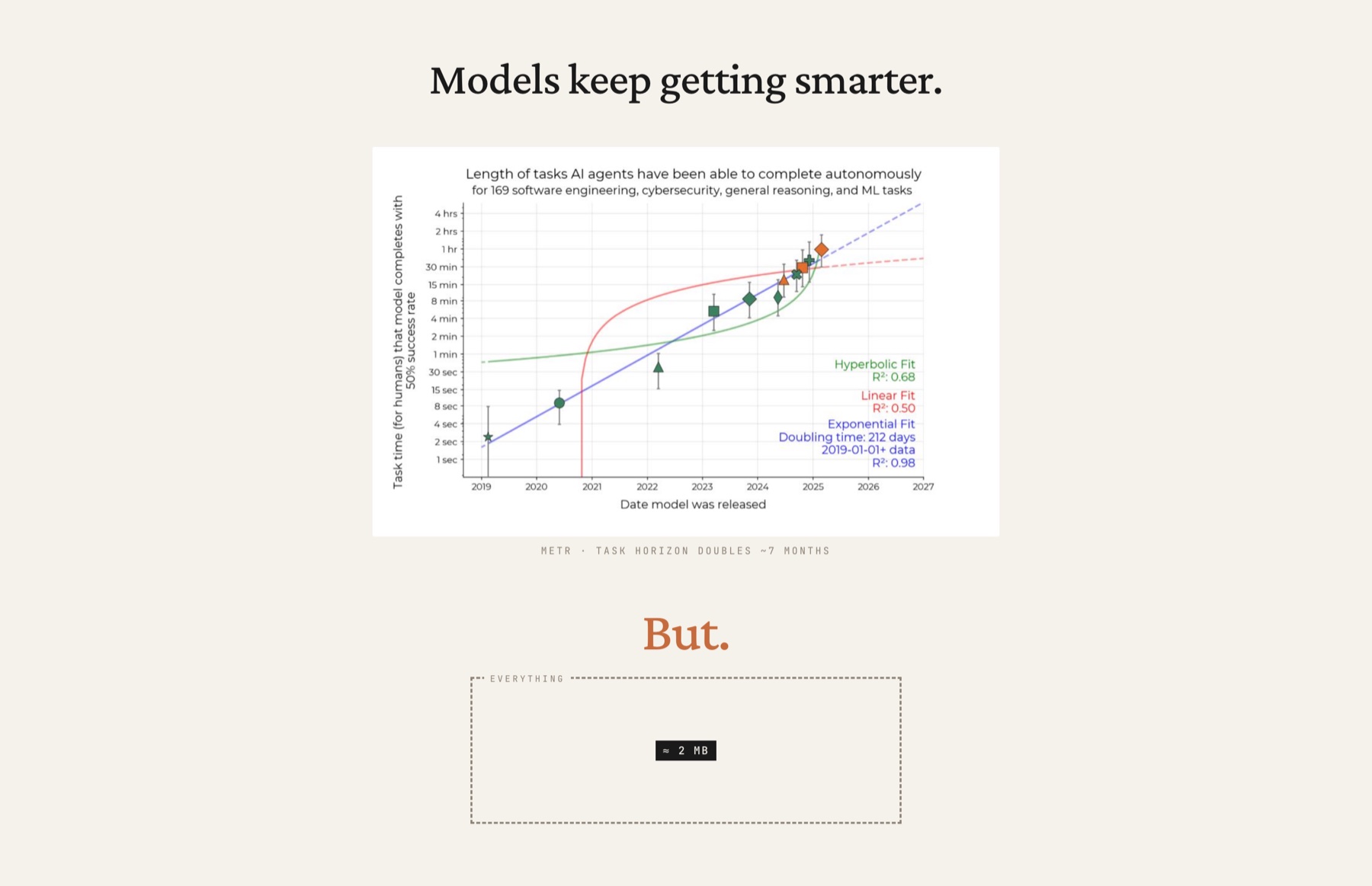
It reminds me of early computers with rope core memory, where they could barely see what was happening at any one time. The intelligence keeps climbing - METR has the task horizon roughly doubling every seven months... - but the window the model gets to think clearly inside of stays small. A lot of what we build is downstream of that gap.
Vibe and fun, versus the bottom of the stack
I want to talk about the distinction, because it's what we internally call the bottom of the stack. We also call it hermetic. And there's a massive difference between data engineering - which in some ways is the final boss, because it tends to sit in the critical path for most companies - and the things you do for fun.

Think of cooking a soufflé for friends. A lot of agentic dev, coding, even some of what we do, lives in that range. People are coming to eat your soufflé, but you can change it to cookie dough halfway through and it doesn't matter. You're the product manager, you're the consumer. You can build whatever you want and change your mind two days in, five days in, and do something else entirely.
Most brownfield work, bottom-of-the-stack work, is the professional kitchen instead. The work needs to be delivered exactly as it needs to happen, or stuff doesn't happen. Or they don't ask you to work there anymore. So most of the agents we've built, from day one, have had to be reliable, repeatable, and dependable.
And here's the honest part: it's not that we started out saying "we know how to make reliable agents," or "we know how to do reliable work with LLMs," which are non-deterministic and so on. We paid a lot of attention, and we learned 300 ways not to do it - by reading the outputs and fixing things. We're now sitting on a lot of information on how not to do this. And incrementally, you make progress.
The genie's list
There's a wonderful Charlie Munger talk from a long time ago - he was borrowing from Johnny Carson - called How to Guarantee a Life of Misery.... Instead of telling the graduates how to live well, he gave them a list of things to do if they wanted to be miserable: all the things you should do if you want no friends, want to die alone, want a miserable life. There's a counterpart someone pointed me to, too - the CIA has a field manual, from its OSS days, on how to sabotage enterprise operations if you're a saboteur dropped into another country.... It's a wonderful list of things you shouldn't do as an enterprise, where you can just read it and find the opposite. Call a lot of meetings. Take a lot of notes where nothing actually happens. That's how you sabotage a company.

I thought that was the right format for this. So the rest of this is a collection of ways to guarantee your agents are never reliable - that the AI work at your company never solidifies, never becomes bottom-of-the-stack, never leaves the greenfield where you just build fun stuff that never makes it into the critical path. The inverse, in every case, should be clear. If it isn't, you can always ask.
No. 1 - Don't ever delete anything from context
Whatever agent you're building or using, stuff everything in there. Skills, as many as you can find. Instructions, as many as you can get. Compact the context often - and don't even notice who's doing the compacting. Summarize it. Add in documents, tooling extensions, your hard drive, your downloads folder. Throw additional stuff in, so that at any point in time you're winning at being able to ruin your own work.

If you have no idea what the agent is seeing, you have no idea what your AI knows, and you have no shared mental model. You're four hours in, context has been compacted four times, and you've stuffed in so many skills you have no idea what's activating at any given point. This is a wonderful way to ensure that if you build something good, you got lucky and it was an accident.
No. 2 - Build everything greenfield. Always.
Whatever you solved last week, throw it out and start over. You get extra points if the stuff you build ends up with so much unintended complexity that you have to rebuild it every time you come back to it. Stop working on it for two weeks, return, and rebuild from scratch. Because new is better than old.

Engineering teams did this before AI, too. Anything that needed to get built greenfield, everyone would fight over, because greenfield is fun. The difference with current AI is that nothing ever leaves greenfield. The fun part is the whole loop now, and the fun part never has to graduate into something dependable.
No. 3 - Pass everything through a model
This is a big one, and most of our partners do it, and so do we. Vibe your skills - how you do things - then give them to a coworker. Have them pass it through a model to summarize so they can understand it, then pass it through another model to write it to their hard drive. When someone else asks "hey, how'd you do that thing?", pass them that vibed version, so they can pass it through another model to look at it.

By the time you have something resembling organizational knowledge, it's been through a model so many times that - wonderfully - your ratio of signal to slop gets a little worse each pass, and a little worse, until by the end it's mostly whatever Opus thought was the right thing to do in that moment. God help you if you're not using Opus when you do this. Codex will do it even without asking - OpenAI's models tend to be opinionated, like a senior engineer who knows they're senior to you and will actively rewrite your stuff because "that was better." Make sure all organizational knowledge keeps passing through models as often as possible.
No. 4 - Mix prompts, code, control logic, and data
Don't have an abstraction layer. Mix everything. Anyone who was around for early web development will recognize this: it's what PHP was, and what came after. Any complex API, workflow, or system you build has some kind of control plane - do this, then that, then if-this-then-this. It has instructions that go into a model. It has evals or data that get passed in. It has plain deterministic code that executes at some point, and it has execution bindings. Mix all of it. You literally can now: go to a model and say "make the thing," and it'll build you a beautiful two-file system where no one can tell what anything is.
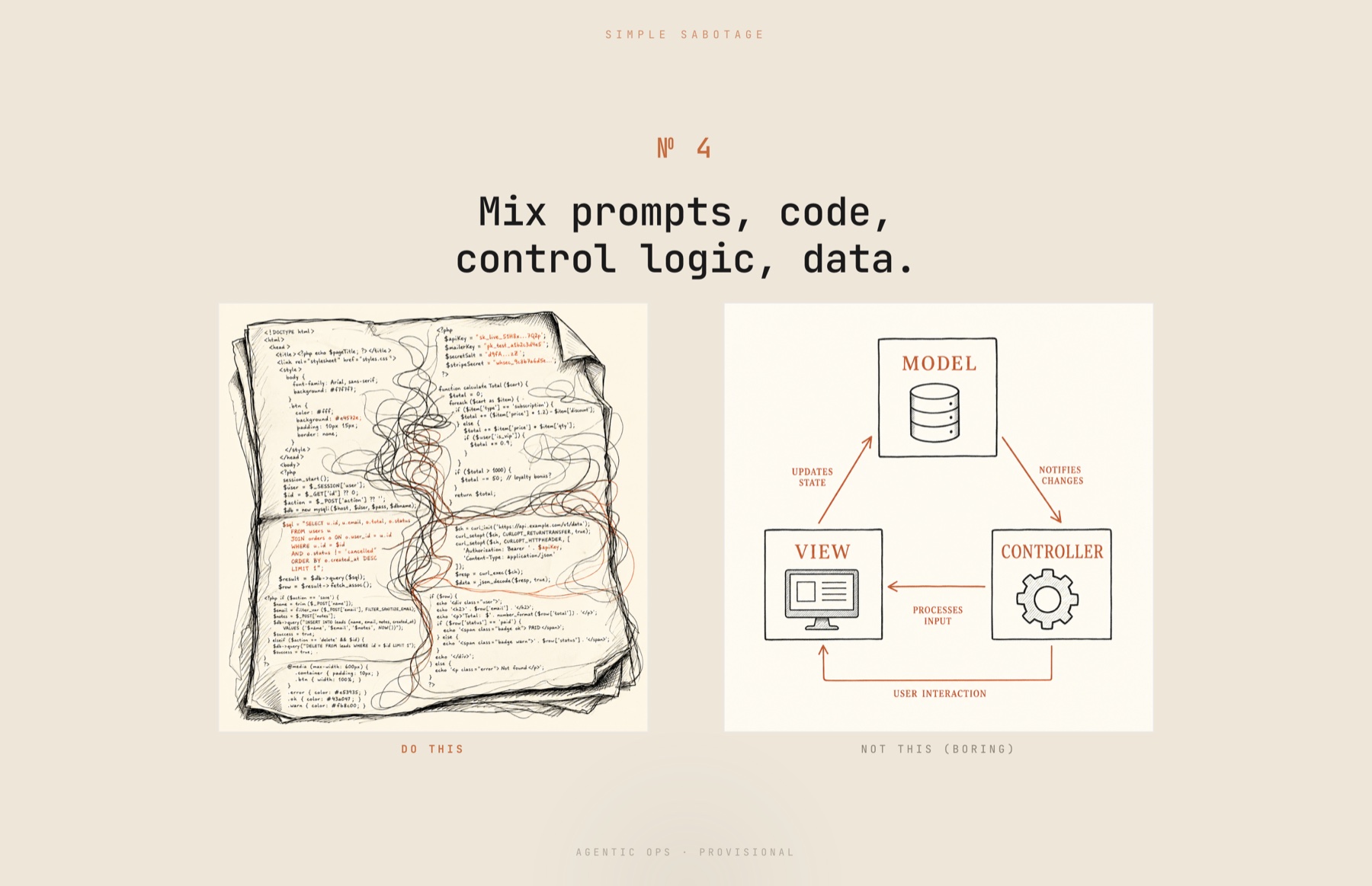
The slide is only half a joke. The tangled mess is labelled "do this." The clean Model-View-Controller diagram is labelled "not this (boring)." Mixing your control flow into your prompts and your prompts into your code is the agentic version of <?php echo $sql; ?> in a template, and the consequences are the ones you remember.
No. 5 - Work in silos
Every engineer on your team, or you, if you're the engineer, should be a wonderful butterfly. Tooling so separate, methods so different, that everyone is their own individual butterfly with their own emergent work habits that nobody else knows. This is one easy way to ensure that when your work actually works, you got lucky.

Everyone gets their own Gas Town, their own Liquid City, their own Vibe Village. If you're lucky, invent your own skills format - but don't give it to anybody else. Then someone else invents what they have, and they hit a different issue, and nothing accumulates across either of you.
Now do the opposite
If any of that resonated, or made sense, or didn't - the inverse is the whole point.

We started building bottom-first for a lot of the data work we did, so the first thing we built was a runtime. Partly because we needed it, but also because the lower down something sits in your stack, the longer it needs to exist to accumulate fixes and get stable. We started building that around June/July of 2025, and open-sourced it a few months later as Hankweave. Open-sourcing it wasn't to sell it forward as a product. It was because we're a tiny team - I always say we're neuron-limited - and open source got a lot more neurons and a lot more diversity onto it. We've had many more people use it, and thankfully just as many people complaining about it and telling me what sucks. Because you can't simulate true diversity. You can't simulate the real world. For bottom-of-the-stack work, you have to hit market, hit real people, and go through the painful process of them telling you "hey, this doesn't work."
So here's the actual answer, in one breath.

For a lot of our work we use hanks, which are just our abstraction layer for AI programs - the place you separate control flow from prompts from code from data, and put each somewhere else. They get broken into codons: individually sequenced units of work, where you specify "this model, this harness, do this, here's what I expect out of it," and then sequence it. They're watched by sentinels, which are watchdog agents that watch the work happen and are themselves reusable. And the whole thing keeps logs and version control that someone actually reads.

The mechanical shape of it is simple. The runtime sequences codons, wipes context between them so each one is a clean unit, lets sentinels watch from the side and write notes, and version-controls the whole thing so fixes accumulate instead of evaporating.
The rule underneath all of it is: don't build what you can reuse. When you reuse, you get the benefit of the last person, and you get to benefit the next one by fixing it. Most of my life and our work has been fixing things, and building things that can be fixed - like old clothes versus fast fashion - rather than building everything greenfield. It's the difference between the clothes we used to have and fast fashion: now you buy a new pair of pants when yours don't work, instead of fixing the pair you have.
You don't have to use exactly this. I genuinely believe you can solve for any of these - pick anything - as long as you have an abstraction layer that you agree on and you force people to use it. It's harder than building whatever you want, whenever you want. But as long as you know what the different pieces are, and you enforce reuse over rebuild, I think you'll be in a good spot.
From the Q&A
I left most of the session for questions, and that's where a lot of the good stuff ended up. A few exchanges worth keeping.
"This feels a lot like building a team for the first time - a team of relative juniors who forget things." Yes. Or a high-churn team. Or an excitable one. That mapping holds up further than you'd expect, and a lot of what follows leans on it.
"How much of this generalizes to just building a good coding agent?" Most of what I'm describing actually sits one level above the coding agent, where we use coding agents as a reusable harness. If you look at Hankweave, we built on Claude Code's agent SDK, because models - through RL, synthetic RL now - are co-evolving with their harnesses. That layer is solidifying so hard: Anthropic tunes on the data they get from Claude Code, adds custom headers, red-team/blue-team tests within days, and ships. So you almost have to use the right harness for the right model. Everything I'm talking about sits on top of that: what gets fed into the harness, and what you want to observe coming out of it.
"You mention a million-token context, but the research says it's really only about 100K on haystack tests. What are you seeing?" Haystack tests for discontinuous retrieval, which isn't that close to what we do. LLMs, like humans, encode information sparsely - I've been talking for thirty seconds and I've largely said one thing, I haven't stuffed twenty factoids in for you to retrieve. So in practice, as long as you're on the same problem and everything follows as a causal chain - "I walked in, set up my laptop, gave a talk" - frontier models stay pretty good up to 400-500K, even 600K, from our tests. But if I stuffed even 100K tokens with completely unrelated facts and tried to get intelligence out of it, it would struggle.
"Why a sentinel watching alongside, instead of a reviewer at the end?" There are roughly three ways to enforce behavior. One: write it in the prompt - "don't be lazy," add some emojis, promise to tip it $100, surround it with stars. Two: the codon approach - let it do its thing, then bring somebody else in to fix it, the way a team brings in a second person to unscrew what the first one screwed. Three: the sentinel - someone sitting next to you taking notes any time you veer somewhere bad, where those notes are accessible whenever you need them. It doesn't interrupt the loop; the agent keeps going, and at condition breakpoints you read the notes and fix things up. We've found that pattern incredibly effective, and cheap - our sentinels run on something like Gemini Flash, because, sadly and happily, it doesn't take much intelligence to point out a mistake. Technically it's just a trigger on the agent loop - "fire when X, Y, Z happens" - and a single LLM call that appends to a file. That's it.
"When agent runs are six to ten hours, is that a single run, or codons stacked?" Multiple codons and steps, but still without termination. Most of what we do is heading toward as-unsupervised-as-possible, which is also why Hankweave has a preflight check - you reason about the run before the first model is called, kind of like a good type checker, so you can catch an inference issue before any model is involved.
"If you're using an AI system to measure an AI system, how do you break the loop?" That's the philosophical core. The question we kept hitting was: how do you use a dumber intelligence to measure the progress of a smarter one? Because evals and sentinels both need to run a ton, so by definition they'll always be a smaller, cheaper, in-some-ways-dumber model with less context. Our answer has been to let the smart models move, but aim the cheap ones at behavior. Like running a team - you can't always tell if someone's functioning by reading every line they wrote, but you can tell when something's off: whether they showered, when they leave, whether you see them at the water cooler. Say we have an ingest pipeline pushing data into Postgres. I reasonably can't tell you whether an individual tool call was right or wrong, but I can tell you what a correct path looks like, and what a wrong one would have in it - you're reading things from outside, you're not making enough calls to the database, most of your calls are bunched into one section instead of distributed. There's a comparison to fuzzy logic in there somewhere.
What this was the warm-up for
This was a fifteen-minute version, in a co-working space, on a Friday afternoon. The fuller arguments - codons, sentinels, budgets, preflights, and why brownfield is where the real work lives - got their proper outings later, as talks at SuperAI 2026 and AI Engineer Singapore. Here those are!
Build agents that get to leave greenfield - reliable, repeatable, dependable - by enforcing reuse over rebuild and letting fixes accumulate.
The runtime we use in production is open-source at github.com/SouthBridgeAI/hankweave-runtime, the docs are at hankweave.southbridge.ai, the philosophy is in Antibrittle Agents, and there's a lot more on evals at olickel.com/everything-about-evals. Thanks to SQ Collective for The Stage. I'm @hrishioa on Twitter, and we're at southbridge.ai.