This is the longer version of a talk I gave at AI Engineer Singapore 2026.
If you'd rather read the talk, the slides are below.
This isn't a talk about coding agents
It is a talk about building agents inside large existing systems — systems with old code, with organizations that carry twenty years of preferences and special cases, and with data recorded long before anyone thought about feeding it to an AI.
We started at Southbridge with that as our second-day problem. We got to it the way most people don't: by trying to build a single end-to-end data pipeline for a customer in early 2025, finding that nothing greenfield survived contact with the next real dataset, and then trying a lot of approaches before any of it stopped breaking on us. We're still finding out what works, but I think we know the shape of what to keep doing.
The shape, when you push on it, looks like a small set of priors. They feel obvious in retrospect, the way most useful things do, and they run against the priors most teams start an AI project with. So I'll lay them out as pivots first and explain each one as we go.
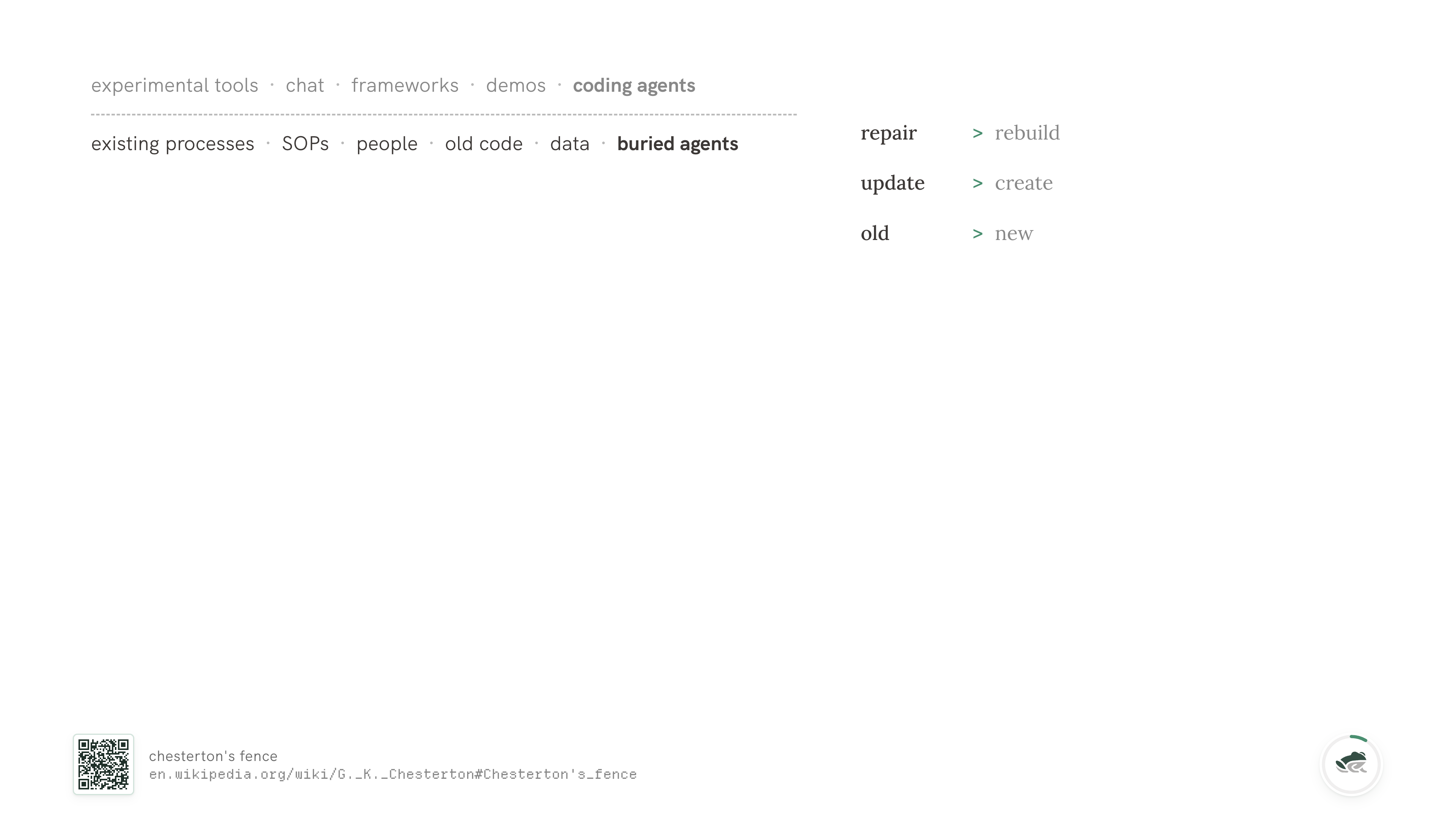
Repair over rebuild. Most of what we ship in production isn't new. The customer has a system that mostly works; the question is whether we can put an agent next to it and not break it. The existing system usually has reasons for being shaped the way it is, even when those reasons are no longer obvious.
This is the old Chesterton's fence point.... If you don't know why the fence is there, be careful before taking it down.
Update over create. Coding agents today are exceptionally good at create. They're getting better at read - text-to-SQL has come a long way. They are still pretty bad at update and delete. Maintenance flows are where most of the actual money in software lives, and they're the part of CRUD nobody is shipping for. Picking an agent system that's good at update is an underrated lever.
Old over new. Almost everywhere I've worked, the bottom of the stack is what makes the company run. The data substrate is older than the team. The internal process is older than the product. The business doesn't get to throw it away to accommodate the agent, and shouldn't have to.
If you start from those three, a collection of primitives falls out the other side. Each one looks like an inversion of what most teams are doing, and you may have run into a few of them yourself.
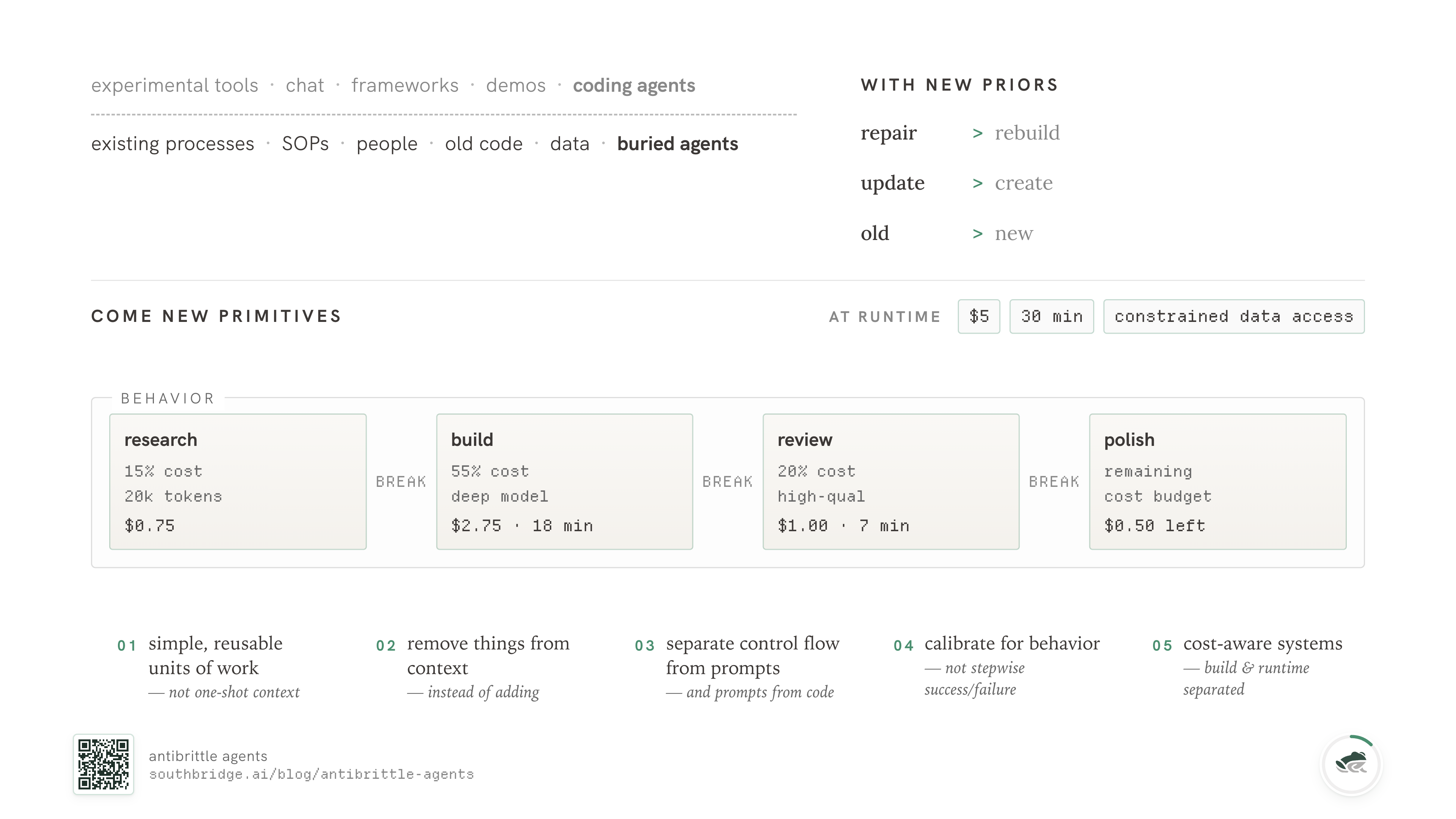
You prefer simpler, reusable units of work over trying to one-shot a context window. Whatever you build that almost works in a long single-shot run is going to break on the second customer. We've never not had this happen. The fix isn't to push the model harder; it's to break the work down so each unit can fail independently and be retried, repaired, or replaced.
You remove things from context instead of adding them. I'm still genuinely surprised how few systems have a way to delete. Many harnesses, frameworks, and products make it easy to add skills, MCPs, instructions, examples, and memory. Fewer make it easy to take any of that out at the right time. The agent's bottleneck isn't always intelligence; often it's signal-to-noise.
You separate control flow from prompts, and prompts from code. I will keep saying this until it stops being controversial. PHP taught us this in the 90s. MVC taught us this in the 2000s. Mixing your control flow into your prompts and your prompts into your code is the agentic version of <?php echo $sql; ?> in a template, and the consequences are exactly the ones you remember.
You calibrate for behavior instead of stepwise success and failure. A few failed tool calls in a long run is not a failure; the right question is whether the overall behavior is converging on the right outcome.
You build cost-aware systems that separate build time from runtime, so you can percolate resources effectively. The author of a workflow knows what costs what. The operator running it has a wallet, a clock, and a database that can only handle so many reads per second. Those are different concerns and they need to live in different places. We'll come back to budgets later because they're the place this matters most.
I lay these out together because they're a single shape. They're what falls out when you start from "the system already works and we're not allowed to break it." If you ship from those priors, what you get isn't another fancy agent demo.
You get to ship outcomes

This is the smallest version of the argument: ship outcomes.
By outcome I mean something concrete. Things that are done stay done. Things that break stay fixed. The system runs the same way next time, and the time after that, with whoever happens to be on the keyboard.
You get to vibe only when you want to — which makes vibing more fun, not less. A lot of vibe-coding is exhausting because every session starts from scratch and re-derives what you already knew. "AI agents" feel hard to land in production because the production version has to do, repeatably, what the demo version did once.
Most of what we've spent a year and a half building at Southbridge is the substrate that makes the second run as good as the first. The rest of this post is what we found.
Before we get to that, let me situate myself.
Where I'm coming from
I've been working on the data problem for about a decade. Smart-contract security in undergrad — the Oyente paper my co-authors and I published in 2016 flagged vulnerable contracts across the early Ethereum ecosystem. Five years at Greywing, a maritime AI company. The central problem at every stage was the same: someone has data shaped a particular way, a decision to make, and a gap between the two.
I started Southbridge to do that bridging full-time. We build data connectors, onboarding pipelines for agents on legacy data, and agentic mining and reporting systems for healthcare, financial, and energy data. Everything in service of the first-mile-of-data problem.
We open-sourced our runtime, Hankweave, in February 2026. Most of what's below is something we earned the slow way — by trying it, watching it break, and being unhappy about it. I'll mention Hankweave where it's needed, and try not to mention it where it isn't.
The problem with starting at data
If you build agents for data, your difficulty starts at maximum from day one.
You're not in the experimental layer of a company. You're not in the chat sidebar. You're somewhere in the middle of the stack, and probably also somewhere near the bottom of it. The work has to be reliable; it has to run unsupervised; it has to survive whatever shape the data shows up in.

A full data run on what looks like small data - verifying formats, doing validation, resolving entities, reconciling across cycles - involves millions of operations, and the errors stack. One percent failure across a million calls is ten thousand bad rows downstream of you. Some of those bad rows will quietly shape a downstream decision.
Context windows haven't helped here. They've actually been shrinking. Gemini gave us 2 million tokens at one point and then quietly came back down to 1 million;... Anthropic and OpenAI hover around 200K with strong drop-off well before that. Whatever the headline numbers say, the practical limit is closer to 2 megabytes of data that a model can think clearly about at once. And even before the hard limit, models get worse at using information in the middle of long contexts....
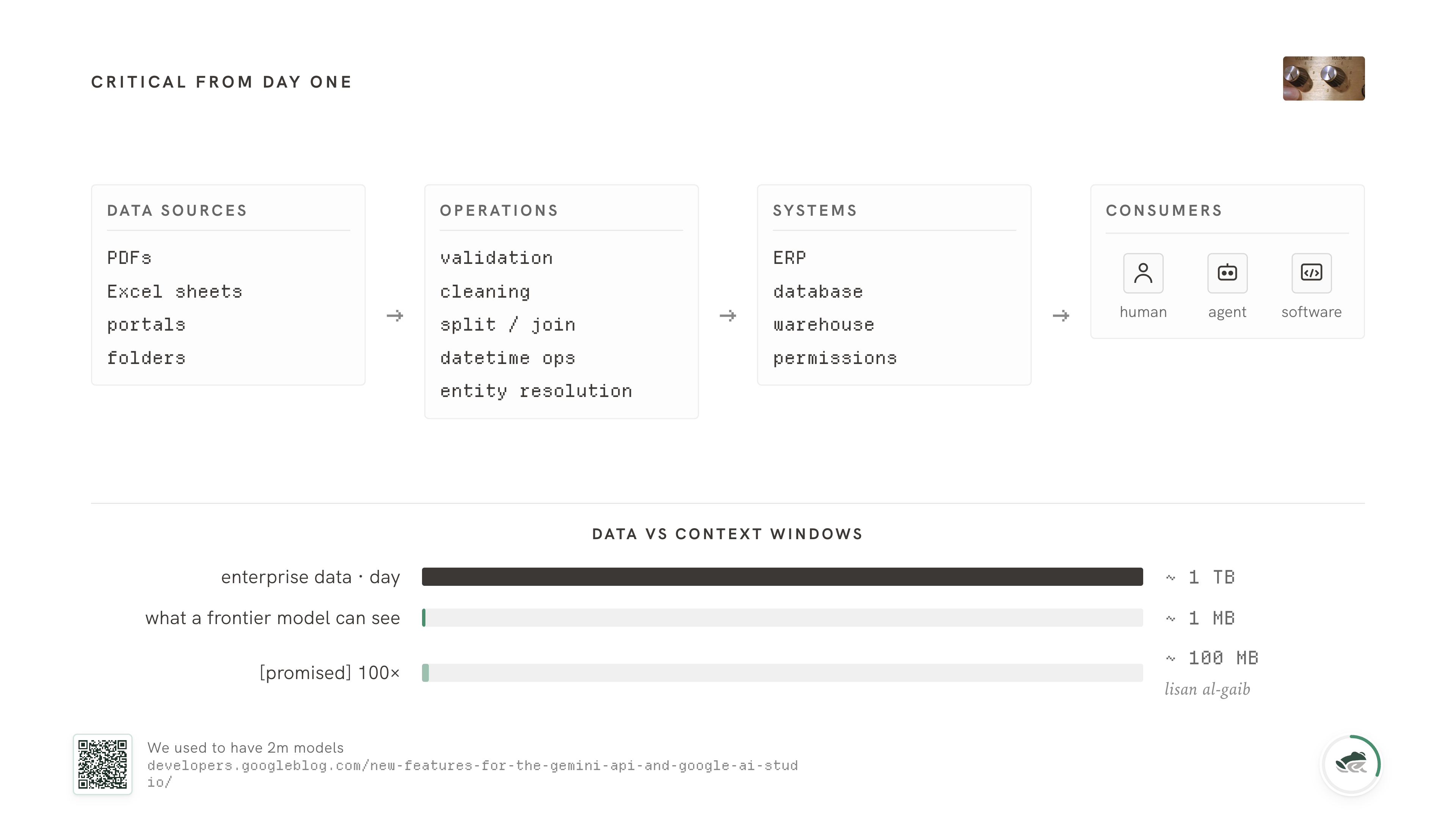
So if you're tempted to wait for context windows to grow and fix this for you, I would not. Even at 100x today's number we're three orders of magnitude away from being able to fit a single day's enterprise data into a single inference call. The gap is structural. We're going to have to engineer through it the long way.
The deeper problem is that data is rarely recorded with the eventual decision in mind. If I write down "32 degrees," that might be enough for someone asking whether Singapore is hot. It is not enough for a weather model, and it is definitely not enough if the decision is whether to launch a missile. Same datum, different decision, wildly different required shape.
There's a second reason data is hard mode, and it's easy to underestimate. So we're going to spend a section on it.
Diversity
The biggest killer of data companies is diversity.
I don't mean "different industries" - though that's true too. I mean diversity in the macro and the micro of how a single piece of data exists.
In the micro, humans turn almost everything they touch into a canvas. Documents, Excel sheets, PDFs, slide decks, even databases - if you give a person a structured medium and ask them to record something they care about, they will reach for the closest available formatting tool and bend the medium until it shows what they mean. Excel is the largest professional canvas in the world.
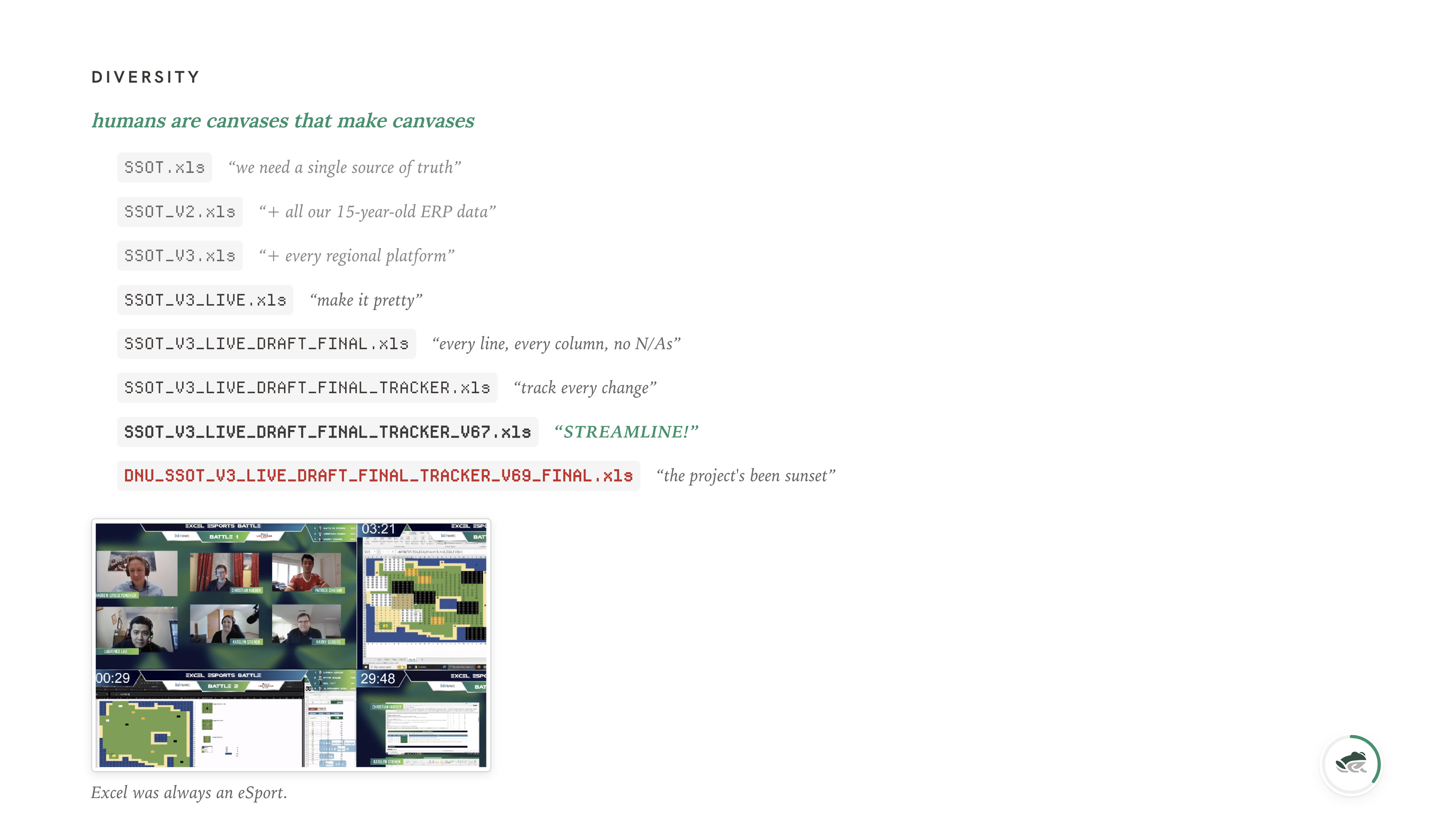
The merge-cell button in Excel was one of the greatest crimes against humanity. It fuses two cells into something that's neither one cell nor two, breaks every aggregation, and makes the data unreadable to anything that didn't put the cells together in the first place. And we love it. We use it constantly. We use it for headers, for "this row spans two months," for "this is a section break." The information is in the merge, and the merge is information you can't get back out without seeing the spreadsheet the way a human does.
There's also an uncomfortable amount of data theater. I say this lovingly, as someone who has made plenty of it. Theater is fine when it helps people see. It's a problem when the artifact survives and the decision it was meant to support disappears.
In the macro, organizations are snowflakes. Different stacks, different programs, different SOPs, different security boundaries. Even the same database, viewed through different intranets and permission systems, ends up functionally different. Snowflake at one company is not Snowflake at another — the tables are different, the conventions are different, the questions people ask of it are different. The product is identical. The instance is unique.

This is the part that kills data companies. There is no universal intermediate format. We tried to find one, and abandoned the premise once we realized that the right intermediate is whatever shape supports the decision the customer is going to make. Decisions live downstream. The shape of the data is determined by the shape of the question, and the question is different at every customer.
So you don't get to write one ETL and ship it. You get to write a runtime that can be told the question and assembled into the right ETL on the day. We'll come back to this when we get to codons.
I'll skip ahead to two separations that turned out to matter much more than I expected.
Online and offline
The first separation: online versus offline agentic systems. Things with a human in front of them, and things without.

As much as we like to think the chat sidebar is where AI lives, most real systems are far more offline than online. The amount of work in any company that doesn't need a human-in-the-loop in real time is enormous. Reports get generated overnight. Pipelines run on a schedule. New customer data gets ingested in batch. Compliance checks happen before a human ever sees the result. Most of the value of an enterprise system is created while everyone is asleep.
You only need an active, latency-sensitive, online human in the loop if you build things fresh every single time. If your agent has no memory of the customer's preferences, no record of the last successful run, no shared state with the previous instance — then yes, you need someone there to provide context. But that's an artifact of how you built the agent, not a property of agents in general.
If you can build systems that ossify over time - where the preferences get learned and stored, where the special cases get caught and remembered, where the same task done a hundred times gets cheaper and more reliable - those systems can move offline. They can run overnight. They can run on local models. They can run for cents instead of dollars. They become appliances: agents that do a job repeatably, thousands of times, without anyone watching.
This is what I think we're going to see a lot more of in 2026. The useful offline agent is often not the smartest possible agent. It is the one that knows the local SOP well enough to stop asking questions already answered. If you're building for that, you build very differently.
The new substrate
The second separation is more contentious, and I'll defend it.
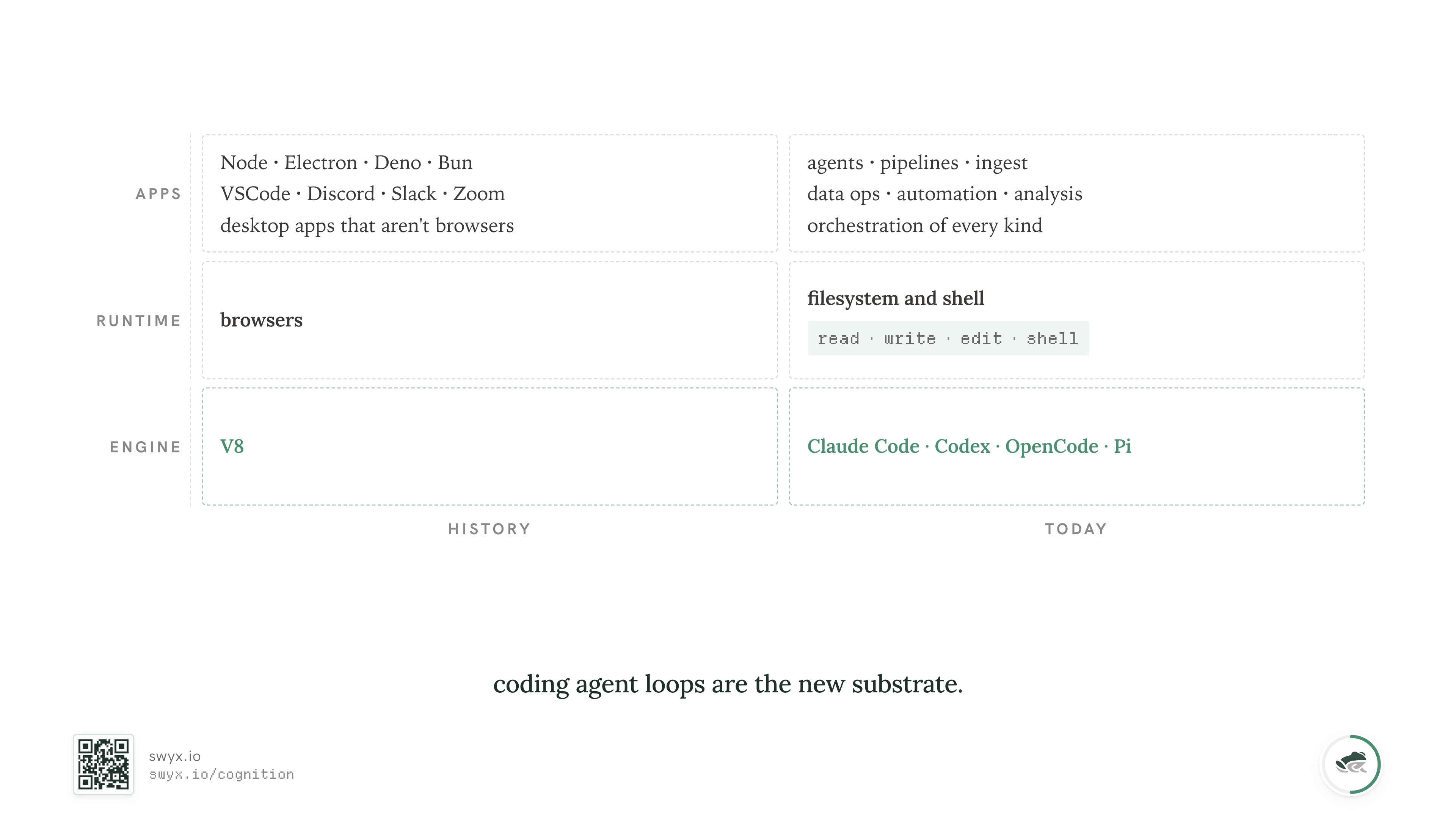
I think coding agents — the loop, the harness, the thing — are already the base substrate for agentic work.
This is not because all agentic work is coding. In fact, I think we'll saturate on benchmark coding very soon. SWE-bench is approaching the same fate as ImageNet did a decade ago. The headlines about coding being "solved" will start landing this year, and they'll be roughly correct for the slice of work the benchmarks measure.
The reason coding agents are the substrate is much simpler than that: they have the most capital, the most reinforcement-learning compute, the most deployment pressure, and the most universal primitives. The average coding agent harness ships native support for read, write, edit, shell - which between them describe most of what an agentic system actually needs to do. Everything else is tools layered over those four.
Claude Code, Codex, Gemini CLI, OpenCode, Cursor's agent: these are getting tuned not just by the labs that train them, but by every customer who runs them and every bug they report. The harness and the model co-evolve. If you build your own harness, you're choosing to race both the model and the harness around it at the same time.
I had to admit this slowly. We tried to build our own harness early on: clean architecture, thick tools, an opinionated model router. The day we tore the whole thing out and replaced the bottom layer with Claude Code as a primitive was the day our reliability numbers finally moved in one direction.
The model will change. The workflow still has to be understandable next quarter.
In the same way V8 and the browser became the substrate for an absurd amount of software that had nothing to do with websites — desktop apps, IDEs, video conferencing, music software, entire operating systems — coding-agent harnesses are becoming the engine layer for a lot of agentic work that has nothing to do with code....
So the right question isn't "should we build a coding agent?" The right question is "given that everyone above us, beside us, and below us is now using Claude Code as their bottom-of-stack engine, what does our work look like one layer up?"
So, what did we learn one layer up? What did we find in the mines of data?
Stop pushing one-shot

Single-shot performance is incredibly fun to push. You jam everything into context: complex instructions, long plans, every skill the agent might possibly need, examples, reasoning traces, the kitchen sink. You compact aggressively when context fills up. You optimize the system prompt across versions. You run a "hero" session to see how far you can push it.
I've done this more times than I want to admit. The car goes very fast.
The thing is — a fast demo is not the same engineering problem as a repeatable system.
Repeatable, reliable agentic work runs counter to the drag-racing instincts. It is just not how you'd build if you wanted self-driving agents.
What does the inversion look like?
You break things into bounded pieces. You give each piece exactly the context it needs, and not a token more. You force handoffs through files instead of conversation, so the next piece can be inspected and the boundary can be audited. You build for the later run, not just the first one. You make boring reruns the default mode.
This isn't graceful. The first time you do it, it'll feel slow. Every other time after that, it'll feel like the only sane way to build.
This is also the missing deploy step for coding agents. A REPL lets you discover behavior. A program lets someone else run it later. Coding agents gave us a new kind of REPL, but not the thing that freezes a working loop into something repeatable.
The way that freeze step plays out in practice has a name. We call the units codons.
Codons
In Hankweave, the runtime we open-sourced earlier this year, the sealed boxes of agentic work — each one isolating a single agent — are called codons. You chain them together to get the behavior you want, and each one is reusable, composable, and inspectable.
A codon is a single block of agentic work: one prompt, one model, one set of files it's allowed to touch. The runtime spawns a coding agent (Claude Code, Codex, whichever you've chosen for that codon), gives it the prompt, and watches the files. When the codon finishes, the runtime checkpoints what changed, optionally clears context, and moves to the next codon.
Codons compose. The output of one codon's checkpoint becomes the input file for the next. Sentinels can be attached to any codon to watch its event stream. Loops can be wrapped around a codon to retry until something passes. Budgets can be assigned per codon - so the cheap codon that summarizes runs on Haiku and the expensive codon that reasons across the whole result runs on Opus.
What this does mechanically is give you trenches. Hard boundaries between subproblems, with the contract between them written in files instead of conversation. Problems in codon 3 don't leak into codon 7, because codon 7 starts with a fresh agent and only reads the files codon 3 explicitly wrote.
Why does this matter? Because the failure mode of long agentic runs is worldline rot: the slow erosion of meaning across the entire context window. Prompts that started crisp become long, qualified, and hard to trust. Tool calls accumulate without ever being collapsed back into "what we now know." Compaction tries to summarize. But the LLM doing the compacting is the most confused entity in the conversation — it's the one with the longest history and no anchor.
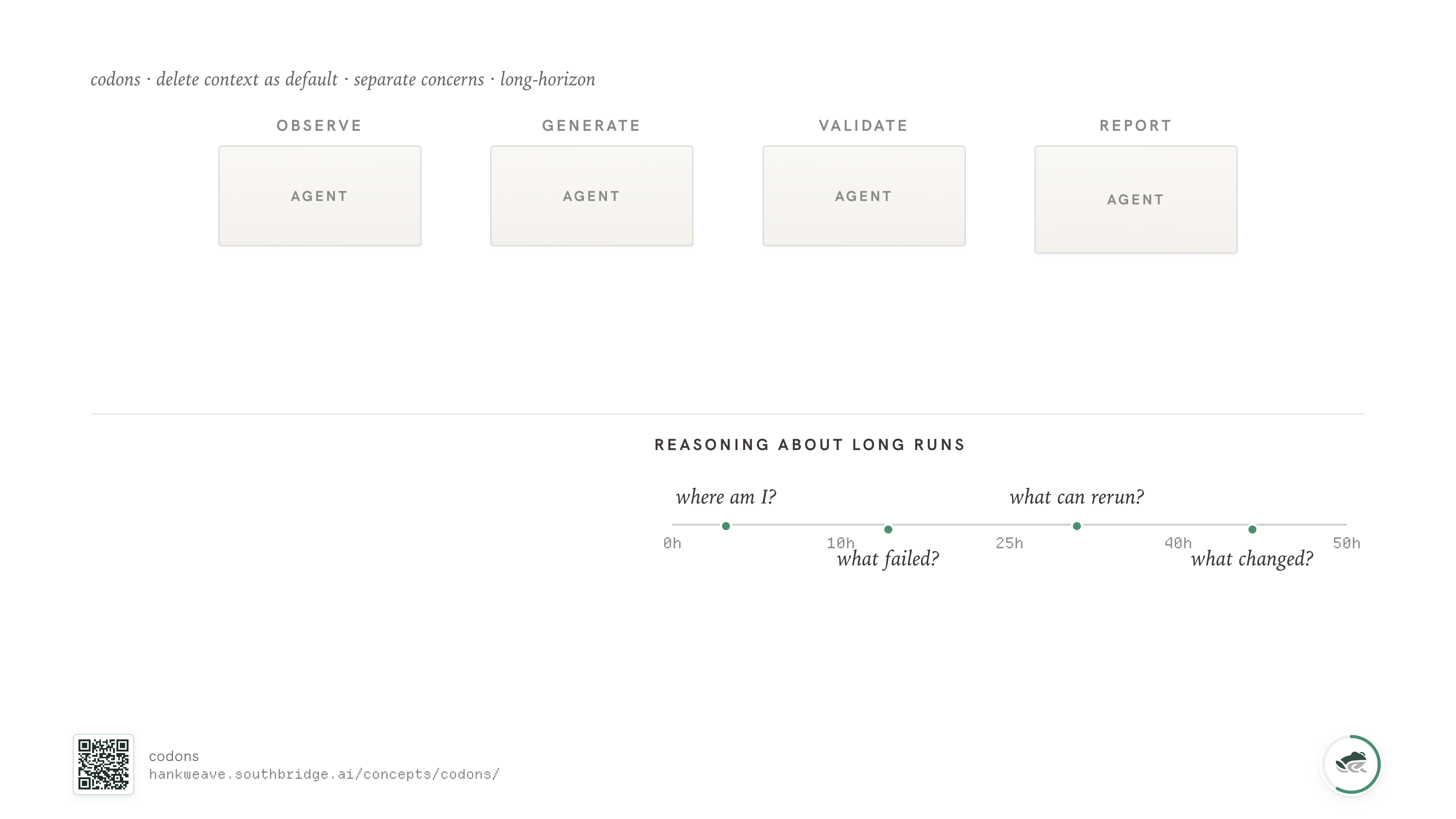
Trenches let us reason about a long run the way humans do: not as a continuous thread, but as a sequence of bounded blocks where state is reset and only specific things are carried forward. Most agentic runs that survive past hour ten do something like this implicitly. We made it the default.
Trenches handle isolation. The companion principle is delete context as default.
This is counterintuitive. A lot of agent design defaults to carry state forward. Many tools give you knobs for "continue previous conversation," "compact and continue," "retain memory." Fewer give you a clean knob for "throw all that away and start fresh, but tell me what you remember."
We default to fresh. Each codon starts with an empty conversation history; if it needs anything from the previous codon, it reads the file. Files are ground truth; conversation history is a probabilistic summary of files we already wrote down.
Be a goldfish. It's good.
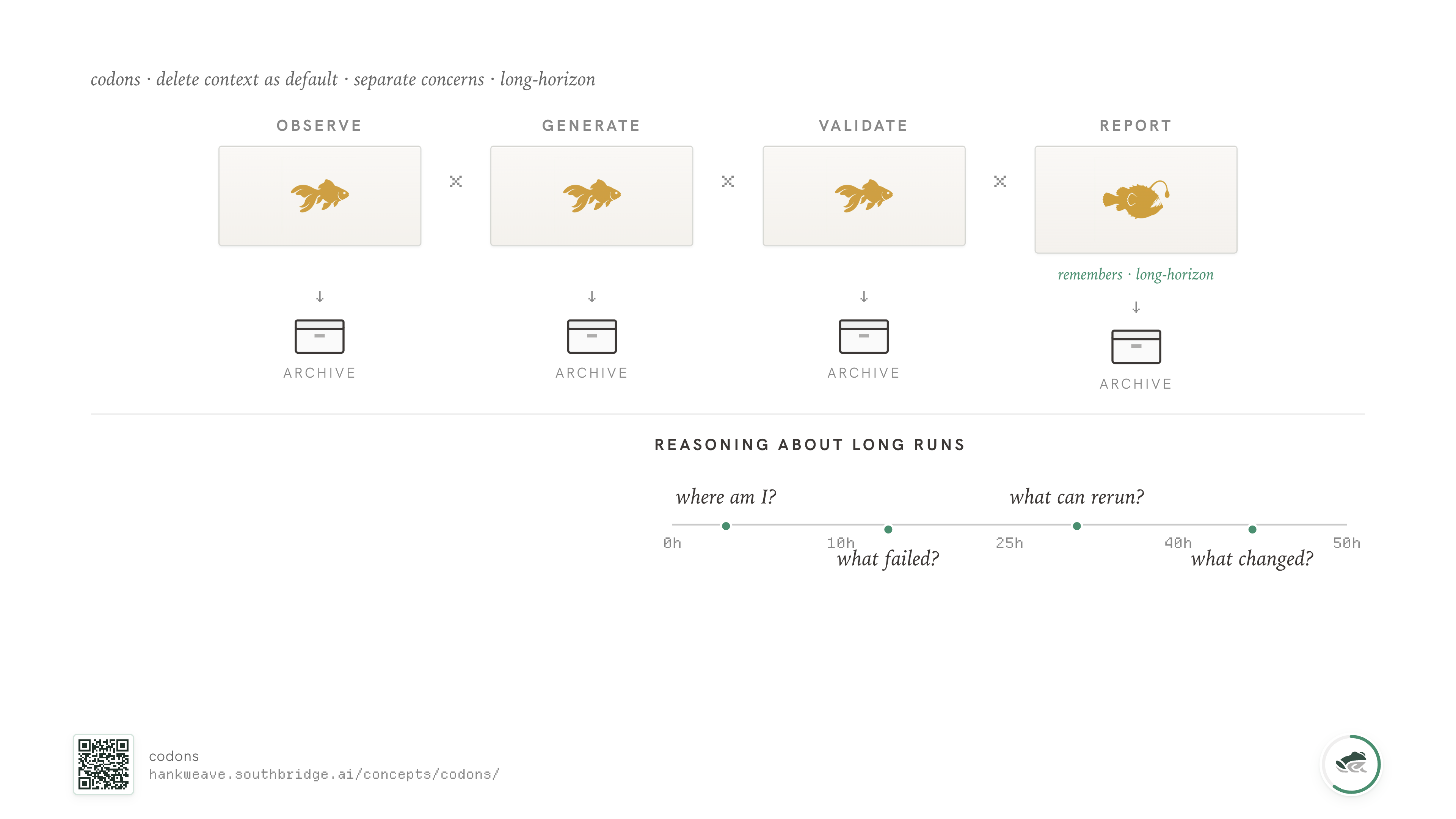
Most codons should be amnesiacs. They should know exactly what they need for the work, do it, write down what they found, and then have their memory wiped when the codon ends. The next codon picks up the file. The system as a whole has a long horizon; no individual agent inside it does.
The only codon that needs long-horizon memory is the one reporting on the run as a whole - and even that one should read its memory from disk at the start of each invocation, instead of carrying conversation state across codons.
The last piece of codons is the structural one, the one we've been re-learning since the 1940s.
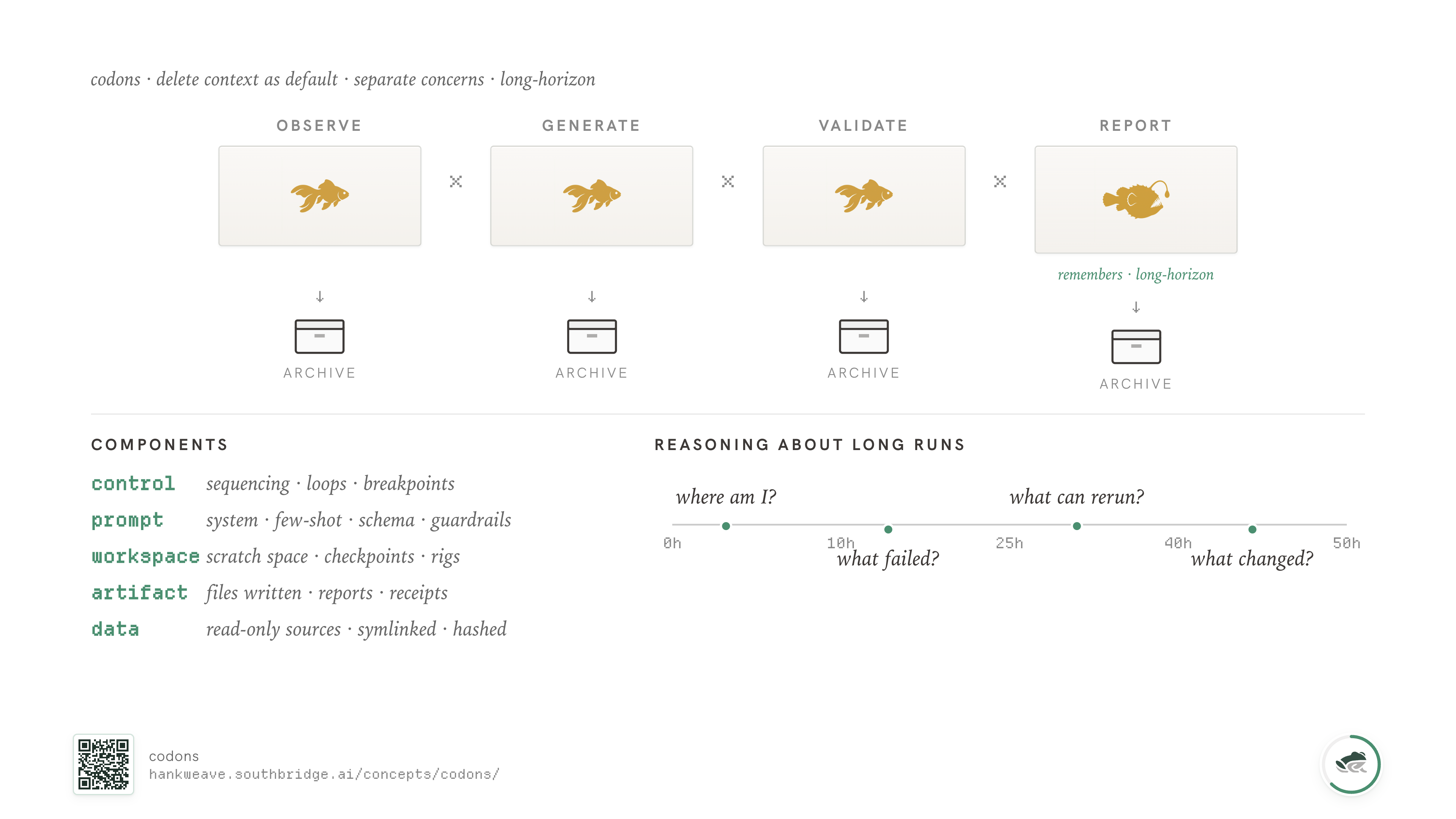
You separate your components by type. Control lives separately from prompts. Prompts live separately from code. Code lives separately from data. Data lives separately from your artifacts - the files the agent actually wrote, your receipts.
This is the von-Neumann/Harvard, MVC-not-PHP-soup, separate-the-things-that-change-at-different-rates argument. It's a lesson computing keeps rediscovering under different names. The consequences are always the same: a system that's impossible to debug, impossible to maintain, and impossible to hand off to anyone who wasn't in the room when it was built.
This gets worse with AI-written code because code already fails to encode intent. A human line of code at least carries weak social clues: maybe someone was rushing, maybe they didn't know better, maybe the business asked for it. With agent-written code, I often have no idea whether a line exists because the model saw two files, because the prompt framed the problem badly, because it invented a local abstraction, or because it was actually the right call. The intent has to live somewhere else.
In the last year my team and I have read millions of words of agent traces. Nine times out of ten, when a system breaks, the cause is one of two things: an opaque abstraction that hides what's actually happening, or a piece of context that didn't need to be there but never got removed.
Both are component-separation failures. If you can find one really useful prior to start your agent project from, the prior is separate the things that change at different rates from each other.
Now, even with codons and clean separation, there's a class of problem you can't solve with a primary thread alone. Some checks can't be done in-band. Some behaviors only emerge over many tool calls. Some things you only want to know about asynchronously.
For those, we have sentinels.
Sentinels
We often build on the principle that the best part is no part. Simple tools, sequenced work, only add things if you absolutely have to.

So I hope it's not a surprise when I say we've never needed parallel agents. A single primary agentic thread has too many benefits to give up, and we'll see some of those benefits in a second.
But for the things that actually need to happen in parallel, sentinels are our equivalent of the event loop. We initially designed them to monitor long agentic runs that would have otherwise taken a human ten hours to babysit. They've since become our most powerful primitive.
A sentinel is an LLM call that triggers on some combination of events from the primary loop. It triggers, fills a context template from the event stream, and writes its result to a file. That's it. There's no callback into the main agent. No interruption. No tool the agent has to call. The main thread keeps doing its work; the sentinel watches from beside it and writes a note.
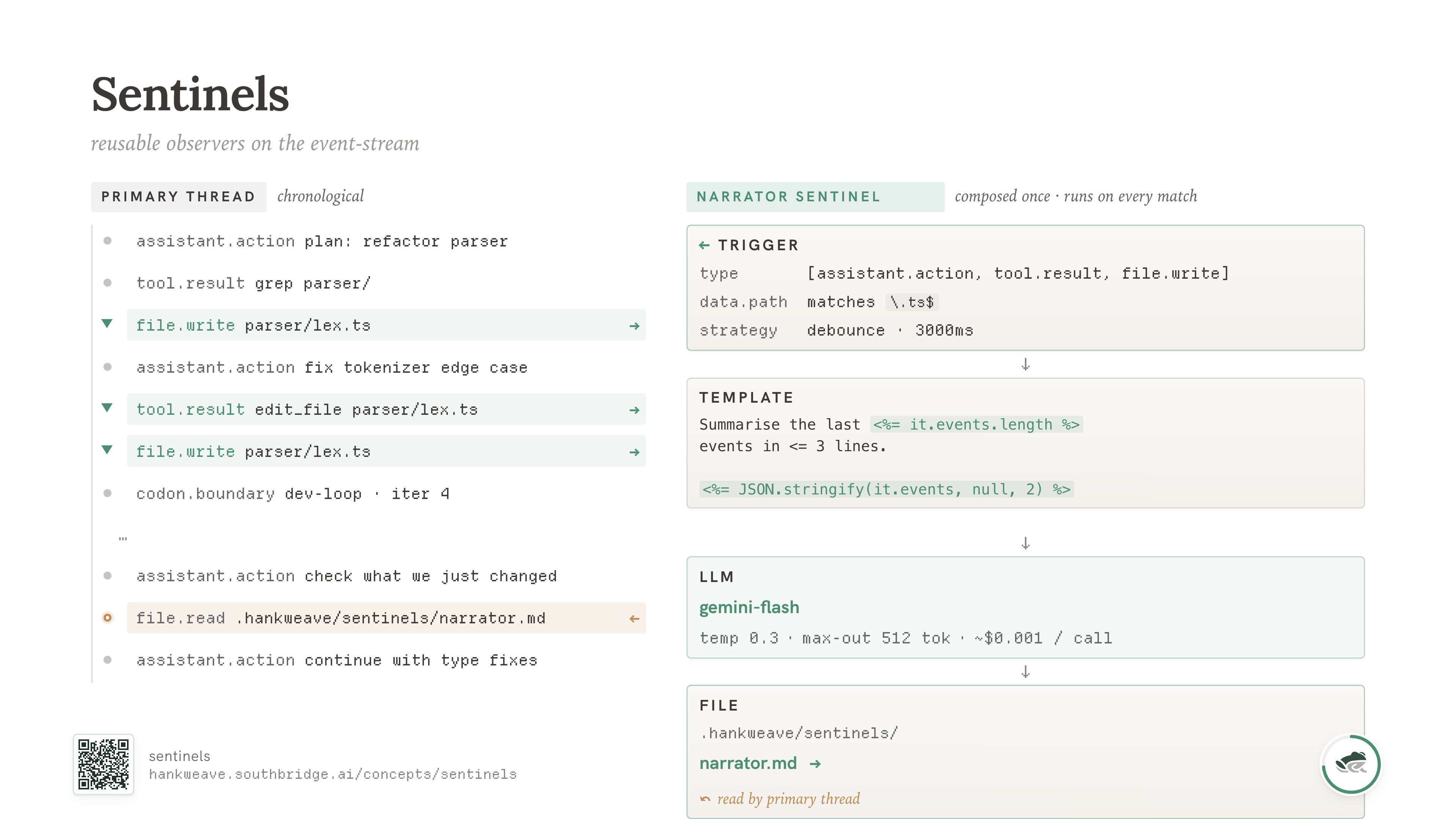
A sentinel could wake up every fifty tool calls and summarize what happened. It could wake up only when the agent writes to a TypeScript file and check for laziness markers. It could wake up only when three errors in a row appear in the event stream and try to figure out the pattern. It could wake up on a fixed clock and emit a status update for an external dashboard.
We use them for narration, cost monitoring, error detection, code review, data extraction, and validation. Almost any check that you'd be tempted to make the main agent do "while it's also doing the work" is better written as a sentinel.
The reason sentinels work is the same reason humans manage other humans this way. You don't tell a junior engineer "while you write this code, also evaluate yourself for laziness." You let them write the code, and you have a senior engineer review it later, with notes that go to a file. The reviewer doesn't need full context of the codebase - they need to spot the failure mode. The pattern is "watch for the thing, write down what you saw, hand it off."
Sentinels are also surprisingly cheap. Most of ours run on Gemini Flash or Haiku. You don't need a smart model to point out a mistake; you need a patient one that's looking at exactly the right slice of the event stream. The cost of a sentinel is a rounding error against the cost of the primary thread.
The useful move is that you can swap what the sentinel watches for. Same trigger, same template structure, different prompt - and now you have a different observer. Same event stream, same agentic loop, but now you're watching for a different behavior.
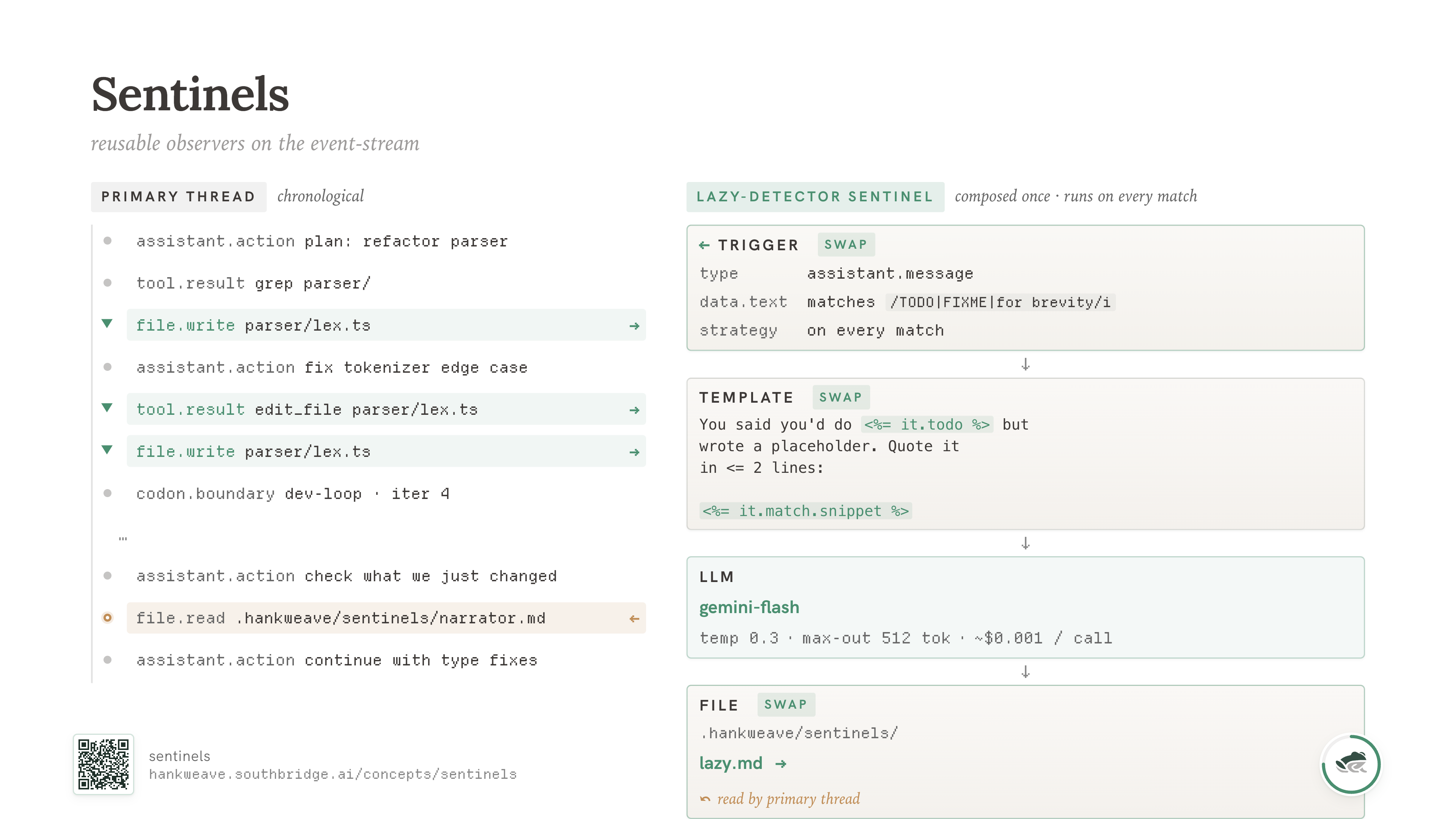
You can swap the sentinel out for laziness. Or mocking. Or bad data hygiene. Or repeated file writes. Or shell errors. You define the pattern you would observe, catch it with a reusable sentinel, and fix it back in the main thread.
This gives the central agent enough freedom to self-correct, while maintaining receipts and accountability. It catches a class of problems that would have required either a much larger central agent (more context, slower, more expensive) or a human in the loop (which we said we wouldn't do).
For us, sentinels have been a better primitive than hooks for coalescing behavior over long runs. Hooks fire at fixed points; sentinels fire on patterns. Hooks are imperative; sentinels are declarative. Hooks have to live in your code; sentinels live in their own files and can be turned on or off without touching the main run.
Sentinels are useful, codons are useful, the separation of concerns is useful. But there's one more piece, and it's the one I think is the most underrated thing in our entire stack.
Budgets
I saved the best for last. Long-horizon agentic systems have to be cost-aware on every axis that matters — and the axes are more than you'd expect.

Not just money and tokens. Time. Data access. Read rate-limits on a production database that you can't hammer just because the agent loaded the wrong skill. Number of customer-facing API calls. Whatever your scarce resource is, your agentic system is going to find a way to consume more of it than you wanted.
If you've done the rest of what's in this post — separation of concerns, single-threaded, clean build-vs-runtime split — you get to build what I think is the most interesting primitive in our stack.
A declarative budgeting system. Which is the best kind.
Like SQL, you express what you want, not how to get it. In a space where the models and the harnesses change every week, declarative is the only thing that won't rot.
Two parties have to agree. The author of a hank knows the internal structure: research is 15% of the work but 30% of the latency; the final review codon should fail if it can't run on Opus. The operator running the hank knows the envelope: a wallet, a clock, a context cap. The runtime takes both, computes the tighter of the two on every axis, and emits a resolved per-codon plan you can read before any tokens are spent.

The author can never increase the operator's envelope — the operator has the last word. The operator can tighten the author's intent but never violate it. If the author marked a codon onExceeded: fail because partial output is worse than no output, no runtime knob lets the operator sneak past that.
Many agent systems give you a global cap. Maybe a per-call timeout. Fewer let the author of a workflow shape the budget alongside the runner of it. The runner ends up either trusting the author blindly or ignoring them entirely; neither is right.
This also changes the finance conversation. The question stops being only "how many tokens did we spend?" and becomes "what changed because we spent those tokens?"
A few things you get almost for free:
- "Give research 15% of whatever budget there is, and let savings flow to later codons."
- "This loop runs as many iterations as it can afford" — variable-length loops, driven by cost, not a hardcoded count.
- Pre-flight the run, see the resolved per-codon plan, decide if you want to commit any tokens at all.
- Run a $0.50 sanity check on Haiku before the $5 real run on Sonnet, without changing the workflow.
Okay. That's the runtime story. What does any of this actually buy you?
What falls out
Do these things, and the benefits show up as second-order effects of the priors we started with. None of them were the goal.

Hanks themselves become AI-executable SOPs. A hank isn't code, exactly. It's a runnable description of a process — the prompts, the rigs, the budgets, the sentinels — that's structured enough for a coding agent to execute and readable enough that a domain expert can review it. This turns out to be the surface where collaboration between agents and humans actually works, in a way that chat threads and standalone markdown files don't.
You get the perfect surface for human-to-human collaboration too. The accountant who knows what the columns in a customer's books actually mean can watch an agent build the hank, see it pull out the rules they've internalized over twenty years, and check the result. That's a different conversation than "let me explain my domain to the AI for an hour." It's "let me watch the AI build a runbook and tell it where it got the rule wrong."
You combine what the AI extracted with what the domain expert knows, in a way that survives the meeting. The next person who needs the same workflow runs the hank. The senior expert's wisdom didn't evaporate when the meeting ended.
Those codon boundaries also give you rollback points. A codon checkpoint is a git commit in a shadow repo. If something goes wrong in codon 7, you don't restart from codon 1. You roll back to the end of codon 6, fix what's broken, and continue. The blast radius of any single failure is one codon.
A long pipeline that fails late does not have to restart from the beginning. It can recover from the last clean boundary.
You can validate hundreds of boring failure cases before a single token is spent.

Most of the failures in our production runs are boring. Missing API keys. Wrong model alias. Input file with the wrong schema. Output path that doesn't exist. Dependency missing. Prompt file that 404s. Rate limit on a database the rig wants to read.
None of these are intelligence problems. They're configuration problems. The runtime can preflight all of them statically before any LLM is involved. We do, and the savings are enormous.

If we know that codon 3 is going to need a particular schema file, we can verify that file exists, parses, and matches the version the codon expects — all before codon 1 starts. If we know that codon 6 needs to read from a production database, we can check rate limits, credentials, and visibility, before codon 5 starts producing data that codon 6 will then drop on the floor.
We catch hundreds of failure cases before a single token is spent. The cost of a preflight is pennies; the cost of a four-hour run that fails at hour three is your afternoon.
The system has the information it needs to recover. When something does go wrong inside a run — and things do go wrong — the runtime has enough state to know exactly what failed, where, and what was last healthy. Depending on the workflow, it can retry a failed codon, downshift when a budget is depleted, or stop at a clean boundary with useful receipts. None of this requires a human watching every token.
You get traceability when reliability fails. As tasks get more complex, the number of judgment calls goes up. The production bar is not "the agent is always right." The bar is "when it is wrong, you can see what it did, what it saw, what it wrote, and which boundary let the mistake through."
And if you can reason about the state of a run better, so can an AI.

The unified event log, the structured hank format, the per-codon checkpoints, the preflight outputs, the budget resolutions — it's all machine-readable by design. Not as an afterthought. Not as a logging tax. As a primitive.
I've watched an agent take a market-valuation report and try to iteratively build a Hank that could reproduce the logic with dummy data. It got far enough to change how I think about the next layer: agents can help discover the workflow, not just run it.
That's an agent observing work, collecting patterns, and freezing them into a runbook another agent can run again. Agents building agents is still early, but it no longer feels speculative to me.
When the substrate is right — when the format is structured, when the boundaries are clean, when the receipts are everywhere — models that know how to write code know how to write workflows. They turn out to be very good at it; better, in fact, than at writing one-shot solutions to the same problem. They have the same advantages a human author of a hank has: they can break the problem down, freeze the working pieces, and rerun.
This is the part I keep coming back to.
Outcomes

You can ship outcomes instead of building tools.
That room — and probably you — is full of people who care about the craft. I'm one of you. I've spent a lot of my career caring about the engine, the harness, the tool. There's a kind of joy in it. I've written a fair amount of internet about it.
But most people are not us. Most people do not care how their dishwasher works, or how their car injects fuel, or which JIT compiles their JavaScript. They want clean dishes. They want to get where they're going in comfort. They have a problem and they want it solved.
Our north star at Southbridge has always been to build and deploy systems that ship the outcome. Which might be:
- A new customer onboarded without weeks of manual cleanup, because the ingest hank handled the customer's specific data shape.
- A research hypothesis checked against real data, because the codebook generation hank turned a messy longitudinal dataset into something queryable.
- An integration time cut down, because the connector hank worked against the customer's API spec and our test suite.
- A production database that survived the agent's curiosity intact, because the budget on that codon's read access was tighter than the rate limit and the runtime knew about it.
- Most importantly, nothing achilles-gunned in the data.
That last one needs explaining. An achilles gun... is a problem you build into a system that fires downstream, much later, and is hard to find and harder to fix. Bad agentic systems leave a lot of these. A wrong unit conversion that survives ingest because nothing checked it. A merged record that should have been two. A plausible-looking summary that papered over a real anomaly. A timestamp that was UTC in one place and local in another.
You don't see the gun when it goes in. You see it when it fires. The customer sees it first, and the trail that produced the mistake is usually hard to reconstruct.
The work is to catch the gun before it goes in. That's what receipts and preflights and sentinels and budgets exist for — they all approach the same problem from different sides.
For agents to ship outcomes instead of tools, they're going to have to become infrastructure — or, in the best possible sense, boring. Repeatable, repairable, observable, cheap enough to run again. Quiet when nothing is wrong, and loud only when something needs your attention. The same on Tuesday as on Friday. The same in the demo as in the second customer.
Build things that get to become legacy

That's how we can build things that get to become legacy.
I want to land on this carefully because I think the word legacy has been a slur in our industry for too long. It gets used as a stand-in for "old, broken, your fault, throw it out." This framing makes adoption harder than it needs to be.
Legacy is not the problem. Legacy is what happens when you build something good enough that other people built on top of it, depend on it, run their lives off it. It's a rare and precious thing. Plenty of software never gets the chance. It is rewritten, abandoned, or outgrown before anyone depends on it long enough to call it legacy.
The person who's been there fifteen years, who knows where all the special cases live, is not an obstacle to modernization. They are part of why the system still works. The data they recorded twenty years ago in a particular shape isn't legacy. It's organizational memory. It's the part of the company you can't rebuild because you weren't there when it happened.
The job we have, if we're going to put AI in the middle of the stack, is to meet that work where it stands. Not ask it to apologize. Not ask it to modernize first. Not ask it to flatten itself into our preferred format so our agent can talk to it. Meet it where it is.
If we do that well — if we build agents that respect the systems they live inside, survive the second customer, can be repaired, and get cheaper and more reliable as they age — then a few of them might survive long enough that someone else builds on top of them. Someone else's engineer becomes the senior who knows where the special cases live. Their work becomes part of the stack.
That's what legacy means, without the sneer. That's what we should be building toward.
Build things that get to become legacy.
There's a lot more in the long version that didn't make it here, mostly because I didn't want to triple the word count. If any of this is useful, the open-source runtime is at github.com/SouthBridgeAI/hankweave-runtime, the docs are at hankweave.southbridge.ai, and we're still figuring most of this out alongside everyone else. If you want to talk about any of it, I'm @hrishioa on Twitter, and we're at southbridge.ai.