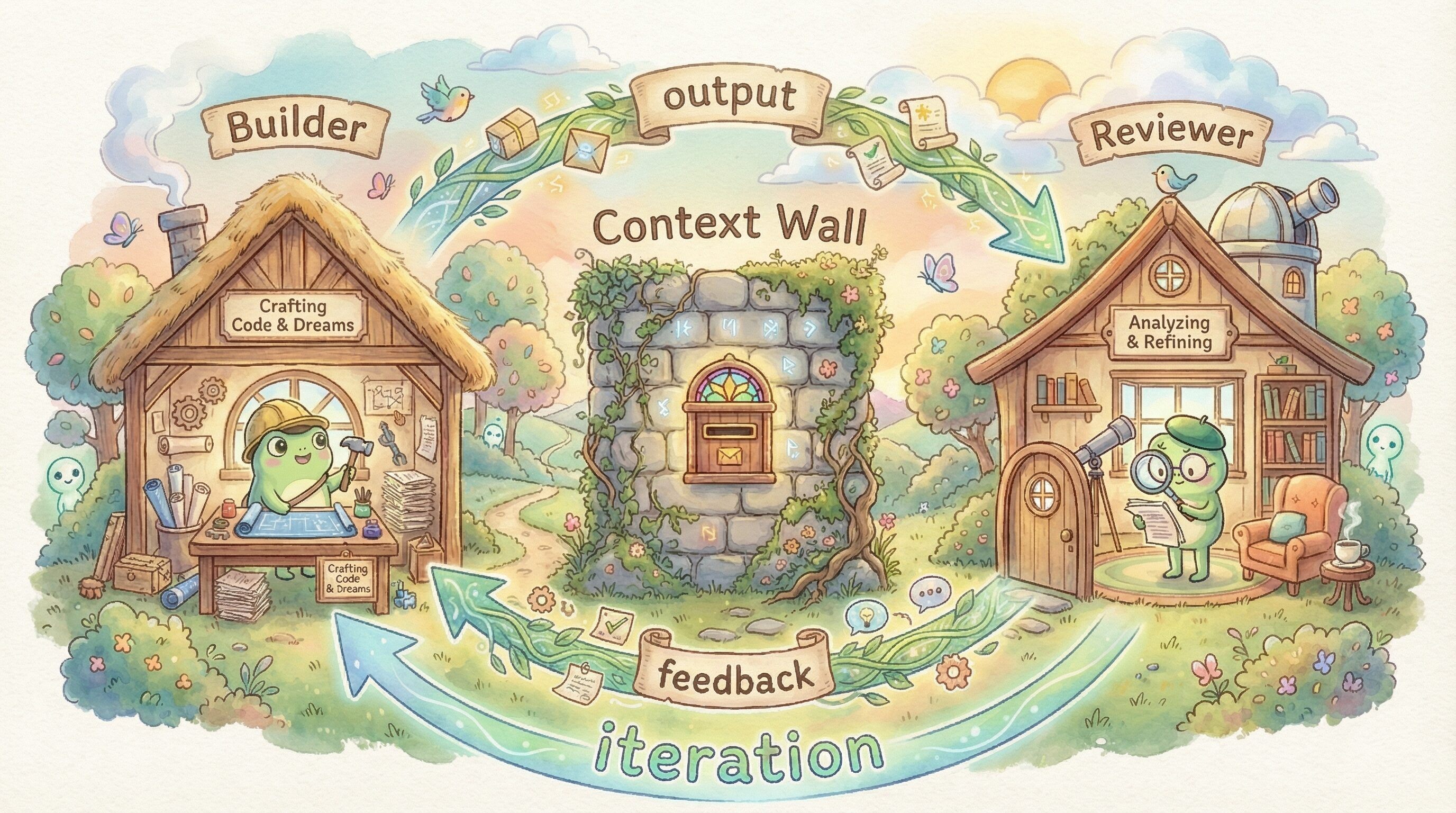
Prithvi Rajasekharan's recent work on Harness Design for Long-running Application Development... is genuinely illuminating — for the new agentic pattern contributions it makes — but also because it seems like a lot of us are independently converging on similar patterns trying to expand task horizon and agent capabilities.
The GAN-inspired Generator and Evaluator model from Prithvi is very similar to the Build-Review codon loop we've been using a lot in Hankweave. It's a crazy powerful primitive, with tons of different ways to deploy it.
The core primitive is simple — and it's something the Agents SDK makes very easy to do: place agents in boxes (Thariq calls them skill boxes, Minu tells me) separated by context walls. One builds, one reviews, and only the output crosses the wall. Prithvi identifies exactly why this separation matters:
When asked to evaluate work they've produced, agents tend to respond by confidently praising the work — even when, to a human observer, the quality is obviously mediocre... Tuning a standalone evaluator to be skeptical turns out to be far more tractable than making a generator critical of its own work.
We've built three variants of this pattern so far, and each taught us something different about where the leverage is.
GAN-style codon loops
Our planning hank — that we use daily to build hankweave and other things — has two such loops with variable iterations embedded in it.
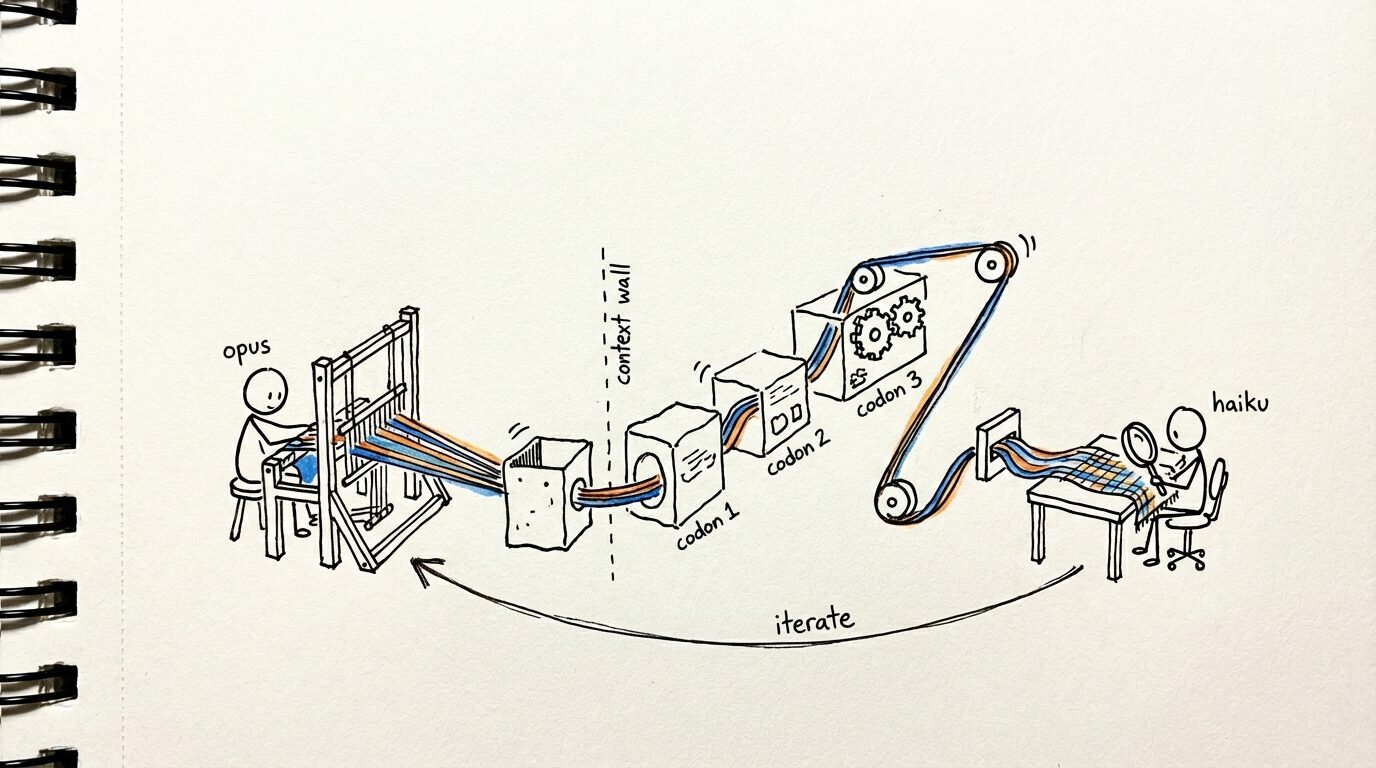
Plan - review - improve plan
The first loop is to generate a plan with opus, review it with haiku. This significantly improves plan quality, and the fresh eyes of the reviewer catches things the writer consistently misses. Hankweave makes it incredibly easy for us to express it declaratively, with the runtime (and the Agent SDK) taking care of execution:
{
"type": "loop",
"id": "blind-reviews",
"name": "Repeatedly improve the plan through blind iteration",
"terminateOn": {
"type": "iterationLimit",
"limit": 3
},
"codons": [
{
"id": "step-5-blind-review",
"name": "Step 5: Review the merged plan with fresh eyes",
"model": "haiku",
"continuationMode": "fresh",
"promptFile": "./codons/codon-5-review/0-review.md",
"appendSystemPromptFile": ["./codons/system-prompt-broad.md"]
},
{
"id": "step-6-update",
"name": "Step 6: Update the plan based on the review",
"model": "opus",
"continuationMode": "fresh",
"promptFile": "./codons/codon-6-update/0-update.md",
"appendSystemPromptFile": ["./codons/system-prompt-broad.md"]
}
]
}Implement - review - update
The second loop is the implementation review loop, where sonnet implements the plan, and opus critiques the results. We use rigs (deterministic code execution in hankweave) to run tests in between the codons, so that the reviewer has a fresh batch before it executes. This is a three codon loop (the open-source version has two), where sonnet writes the code, opus reviews the results, and another codon updates the original plan with the results.
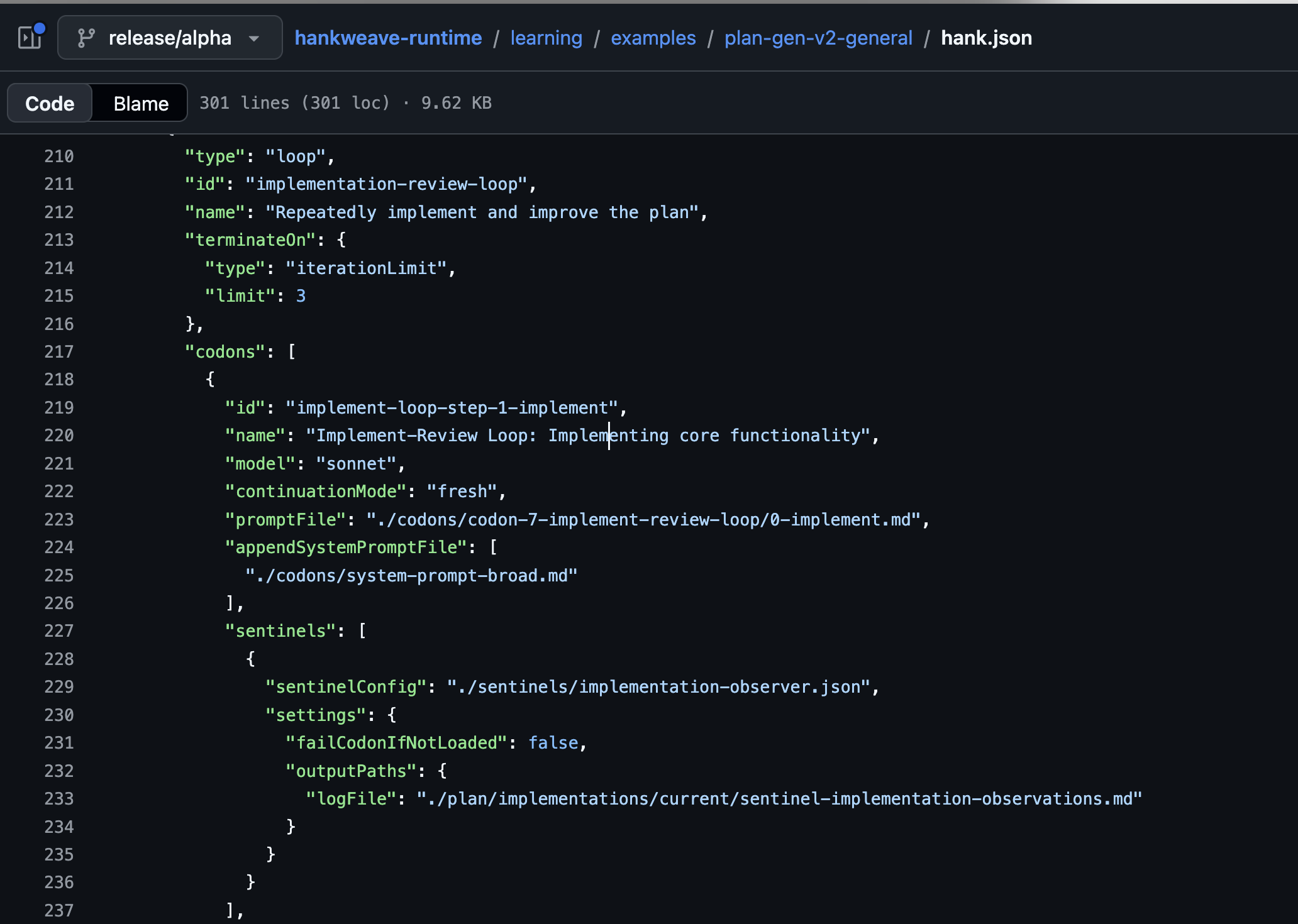
Here, we find that using smarter models to traverse the code improves critique results — since we need them to spin up in a token-efficient manner from fresh context, get situated, and provide critiques of the implementation.
We also found that deterministic prostheses — like scripts that extract out diffs, auto-run tests — had a huge lift in improving agentic performance, instead of expecting the agents to write and run them as needed. Imagine if you needed to write your own webservers any time you needed one!
This maps directly to one of Prithvi's findings: his evaluator used Playwright MCP to interact with the live page before scoring — navigating, screenshotting, exercising the app like a real user. That deterministic test surface is what made the evaluator's feedback actionable rather than hand-wavy.
Make - look - change
Interestingly, this is also huge (as Prithvi writes as well) for visual reflection. Our comic generation hank uses Opus codons to review the generated characters, check comics for consistency, etc, with separate codons for story writing and generation. These loops significantly improve comic quality — and we use them both for broad improvements (for emotional impact) but also to fix small, finicky issues.
For example, here is the same comic panel across three iterations of the review loop:



And for example, here's part of the review 1 notes:
## panel-05.png (Strip 5: "The Cascade")
**Verdict:** NEEDS_WORK
**Intended emotion:** The peak of chaos — the reader should feel overwhelmed.
**Actual emotional read:** Partial. The cascade logic is THERE — you can see the leaf deflecting the fountain, the fish eating moss, Sheldon falling. But text problems drag it down.
**What works:** Panel 1 shows the leaf deflecting the fountain, with fish visible below and browning algae hinted at. Panel 2 has Sheldon on his rock with "Oh no." — correct. Panel 3 has Sheldon upside-down in the water — correct and funny. Panel 4 shows chaos wide shot with "After that, he stopped counting." — correct. The Blue Puffball is visible in Panel 4 background.
**Issues:**
- **HARD FAIL: "I TOLD HIM." speech bubble appears TWICE in Panel 3.** The text is duplicated — two separate speech bubbles both saying "I TOLD HIM." This is a hard fail criterion (same text appearing twice).
- **Panel 1 has garbled descriptive text rendered as a caption:** "Ribbit, the successfully proped a leaf to deflect the fountain spray away from his friends." and "...The algae is turning brown and wilting." — These are scene descriptions rendered as visible text. The first is also garbled ("proped" instead of "propped"). The prompt specified NO dialogue for Panel 1.
- **Panel 2 has garbled descriptive text:** "Without the algae to eat, group desperaely nibbling the most the moss off the rocks at the edge." — Garbled prompt description leaked as visible text.
- Strip title "The Cascade" appears at top — slightly unusual but not a fail, just a style note.
- Panel 4: Ribbit appears to have a different body shape (more frog-like, less tadpole-blob). Minor consistency issue.
**Wrench visible?** YES — Panel 1 and Panel 4.
**Prompt update needed:** YES — Major. Same text-leak problem as panel-02. Need aggressive text separation. Also need to fix the duplicated "I TOLD HIM." by adding "CRITICAL: Each speech bubble must appear EXACTLY ONCE. Do not duplicate any text."You can also see panels improve in fine detail as they go through iteration:



Uploading the trace to Braintrust, we can see the loop:
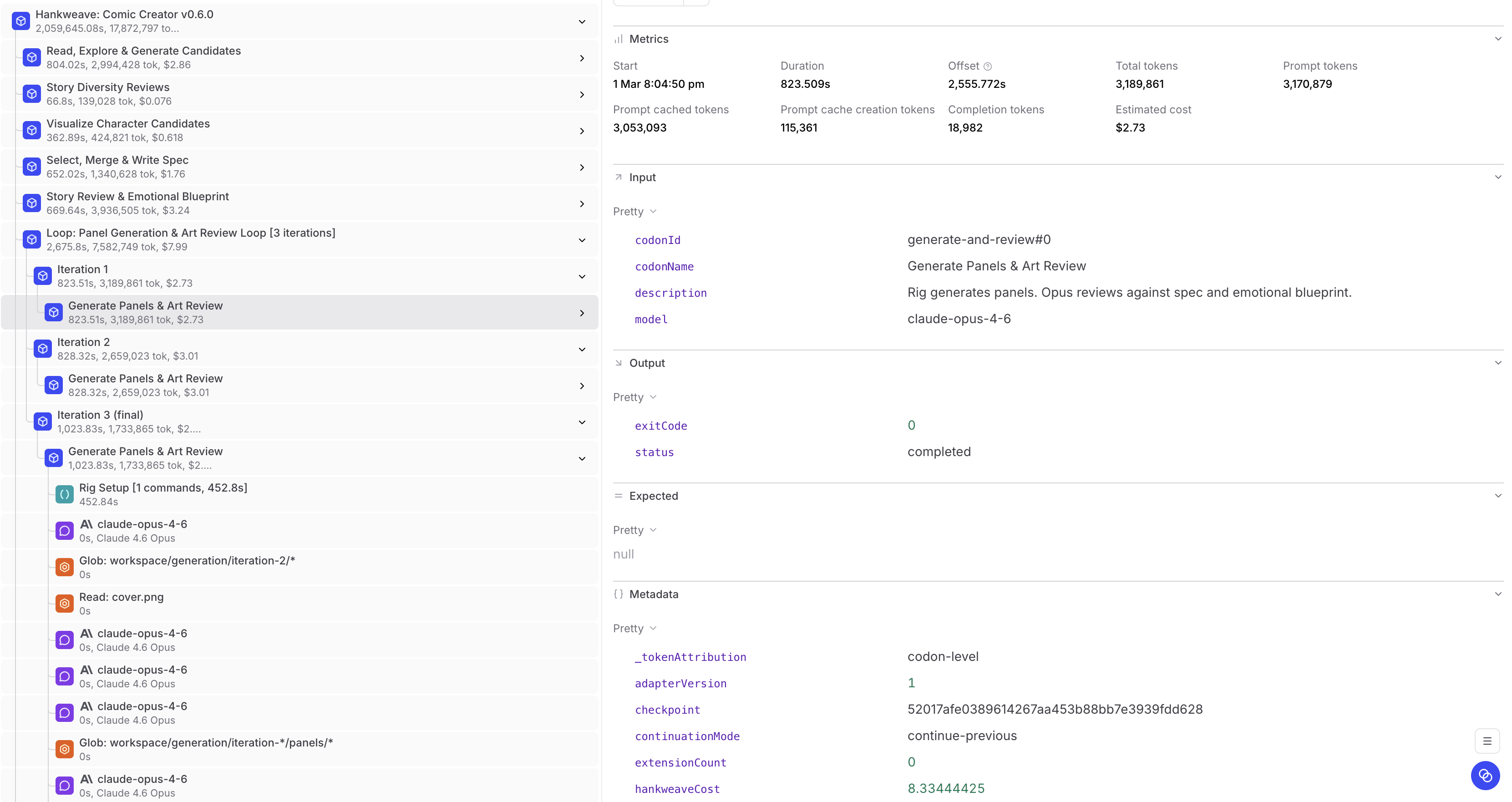
But it's worth noting that there is a second type of loop that we've begun upgrading to that runs much cleaner.
Automated review surfaces
Another type of looping agentic structure is one where part of the work is non-agentic. Clausetta (our connector generator for hankweave), and the new comics hank v2 both use this method.
In Clausetta, we have two loops — one for building, one for evaluation. In both cases, the review surface of the loop is non-agentic. For evaluation for example — a fixed eval suite is run using rigs, and the agent starts fresh with each run's results and attempts to continue the build.
These loops can be more effective in cost, determinism and quality. The new version of the comics hank runs in 1/10th the overall cost, while producing better comics overall.
In most cases, asking "What is an agent doing that we don't need an agent for?" can be extremely useful.
Generating the comic panels? Turns out you don't need an agent for that.
Fetching documentation? Turns out you don't need an agent for that.
When you switch from an agent to a fixed surface for the review and repair loops, what you lose in flexibility and general intelligence you make up in repeatability. In a lot of cases, instead of ( Agentic build + Agentic Review ) x 4, we had better results from (Agentic Build x Automated Review ) x 5 + Agentic Review, for example.
Prithvi arrives at a similar principle from the opposite direction — he notes that "every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing."
Continuous improvement surfaces
GAN-style codon loops can be useful for agentic self-improvement, but they also provide one often overlooked benefit: making the cost-to-output surface more continuous in non formally-verifiable situations. What do I mean there?
With agents today, the cost-to-benefit surface isn't continuous. With coding agents (or agents of any kind), it often looks like this:
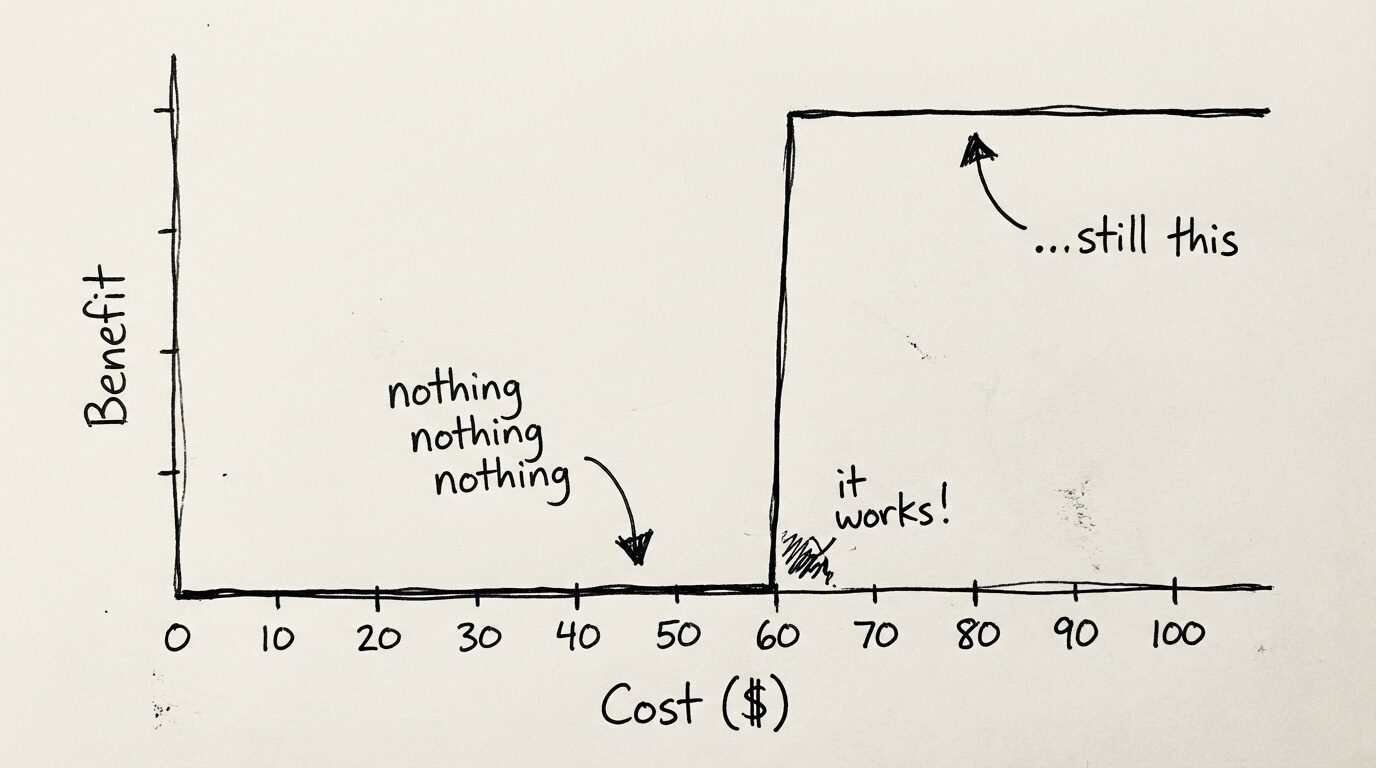
Spend $9.99 and you get no benefit. Spend $10.03 and you get 10 units of benefit. Spend $200 and you get 10.01 units of benefit.
What we want is a continuous curve we can tune. Agentic loops — combined with budgets — allow us to do that. With codon loops, we can get the curve looking more like this:
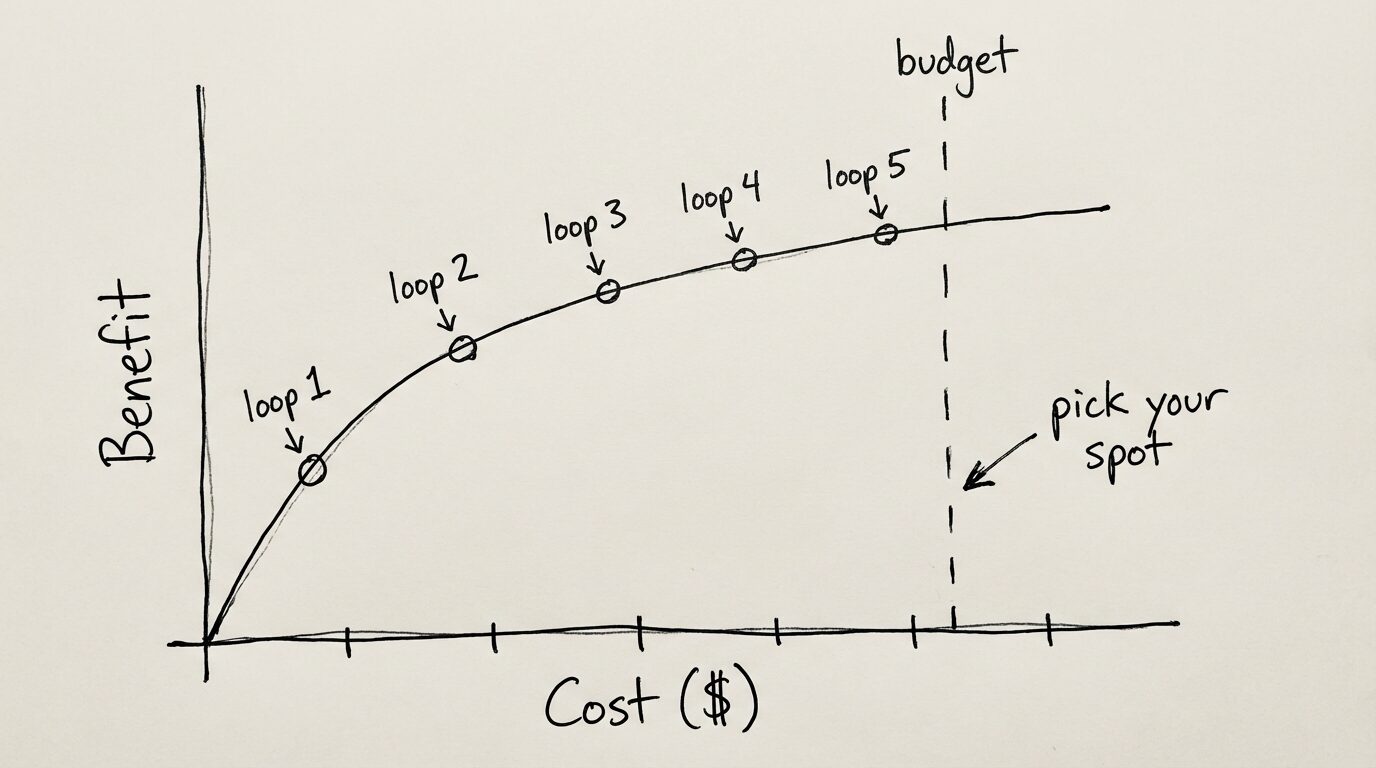
It's wonderful to see more work in long-context problems. As context windows have stalled (at least for now), work on extending task horizon will likely involve some amount of context gating — our method for doing this is codons, or Sealed Agents as we once called them — but there are others. Additionally, repeatability will quickly become the problem to solve as we extend tasks. If we can't rely on step 1 to complete the same way every time, there's no point thinking of step 2.

This is the first in a series on agentic programming patterns we've discovered and implemented through Hankweave.
If you're working on similar problems, reach out — I'll happily send over the hanks or runs.
For more on our thinking about building durable agents, see Antibrittle Agents and the Hankweave launch notes.