I still can't forget the day I first watched a Bambu Lab printer start a job.

It doesn't just print. It taps the bed - force sensors checking whether the surface it trusted yesterday has shifted overnight. It draws thin lines of filament and scans them with a LiDAR that resolves to seven micrometers, measuring how the plastic actually flows versus how it should. It checks the first layer with a patience that would be maddening in a person - line after line after line, comparing what it laid down against what it intended.
This takes a few minutes.
But this is why a Bambu prints the same part on Tuesday and Friday. Summer and winter. Fresh filament and old. The printer trusts nothing. Not the bed. Not the filament. Not even itself from yesterday.
The ritual is the reliability.
We at Southbridge 3D-print quite a bit.
On our latest, here are some Frognus we printed out for friends and families:

We've lately been using Bambu Labs for most of it. And every time I think about how that printer works, it reminds me of what we do with Hankweave. There's some uncanny resonance between a Bambu and a Hank, other than their fun-sounding letterings.
What makes Bambu interesting isn't the speed, or the enclosed chamber, or the multi-material system. Other printers have versions of all of those. What Bambu got right is that they took verification seriously as a design primitive.
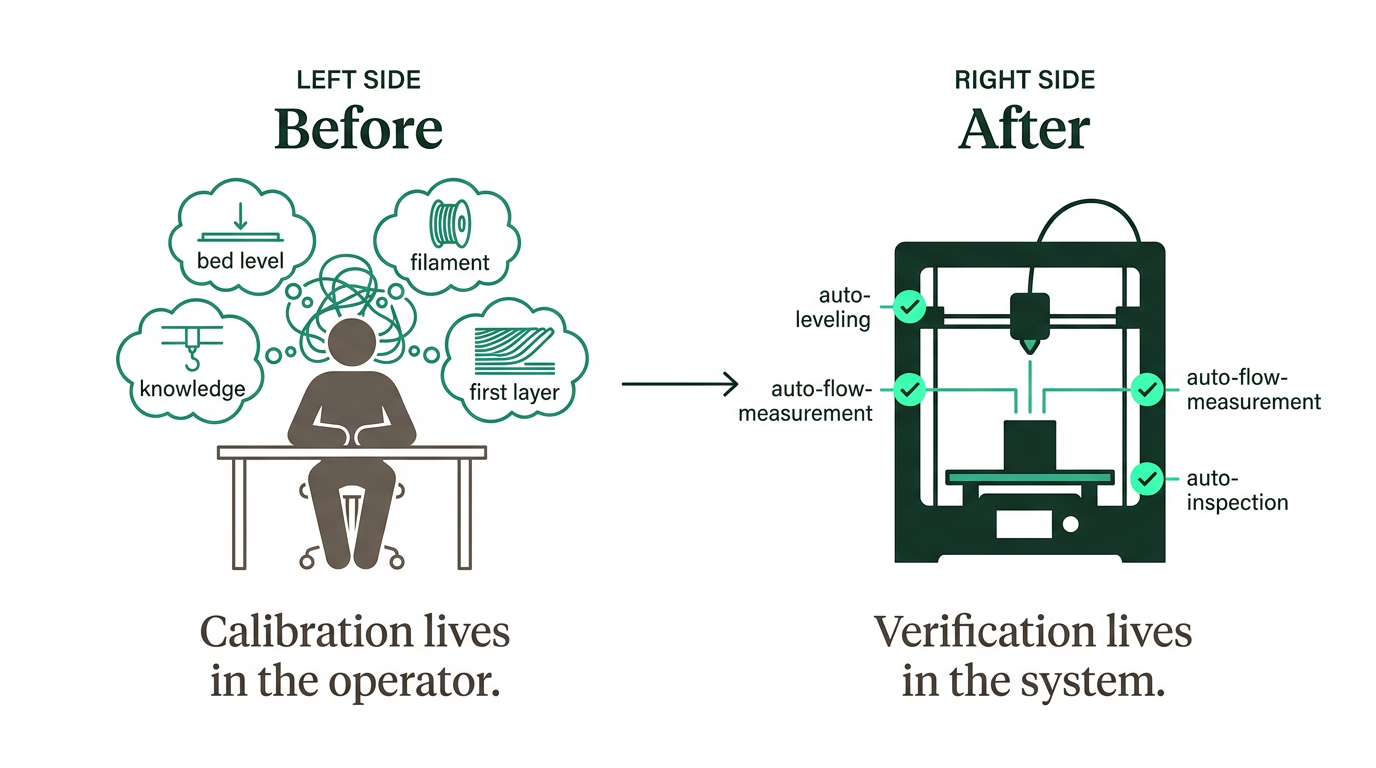
Before Bambu, calibration was something you did yourself, once, and hoped it held. You'd level the bed manually with a piece of paper, eyeball the first layer, adjust on the fly. It worked if you knew what you were doing. It didn't transfer to anyone who didn't.

Bambu made verification automatic, continuous, and structural. The bed gets checked before every print - not because you remembered to check it. The flow gets calibrated against the actual filament loaded right now, not the one you profiled last week. The first layer gets inspected by something more patient than you are.
The result is people like my mom who know nothing about 3D printing get reliable results. Not because the machine is simple - it's extraordinarily complex - but because the complexity lives in the ritual, not in the operator's head.
This is the part we kept thinking about.
Here's where AI agents are right now.
You probably know someone who can do extraordinary things with AI. Maybe you're that person. They run agents, supply context, get things built in minutes that would take others days. But the knowledge of how they do it doesn't really leave them. It lives in their heads, in conversation histories, in instincts about when to push and when to let the model run.
This is the pre-Bambu moment. Calibration lives in the operator. Results depend on who's at the keyboard. The capability is real, but it isn't transferable and it isn't repeatable.
And until recently, that was fine. AI tools were interactive - you sat alongside them, steering and correcting in real time. The human was the reliability layer. If the agent drifted, you caught it and pulled it back. The interaction was the calibration.
But the direction is changing. Agents are starting to run autonomously - processing data, generating code, building systems - for hours, without someone watching. Real automation, not assisted typing. And when the human leaves the loop, the question shifts from "is the model smart enough?" to "do I trust it enough to let it run?"
That trust needs to be built carefully. You don't get to skip the ritual.
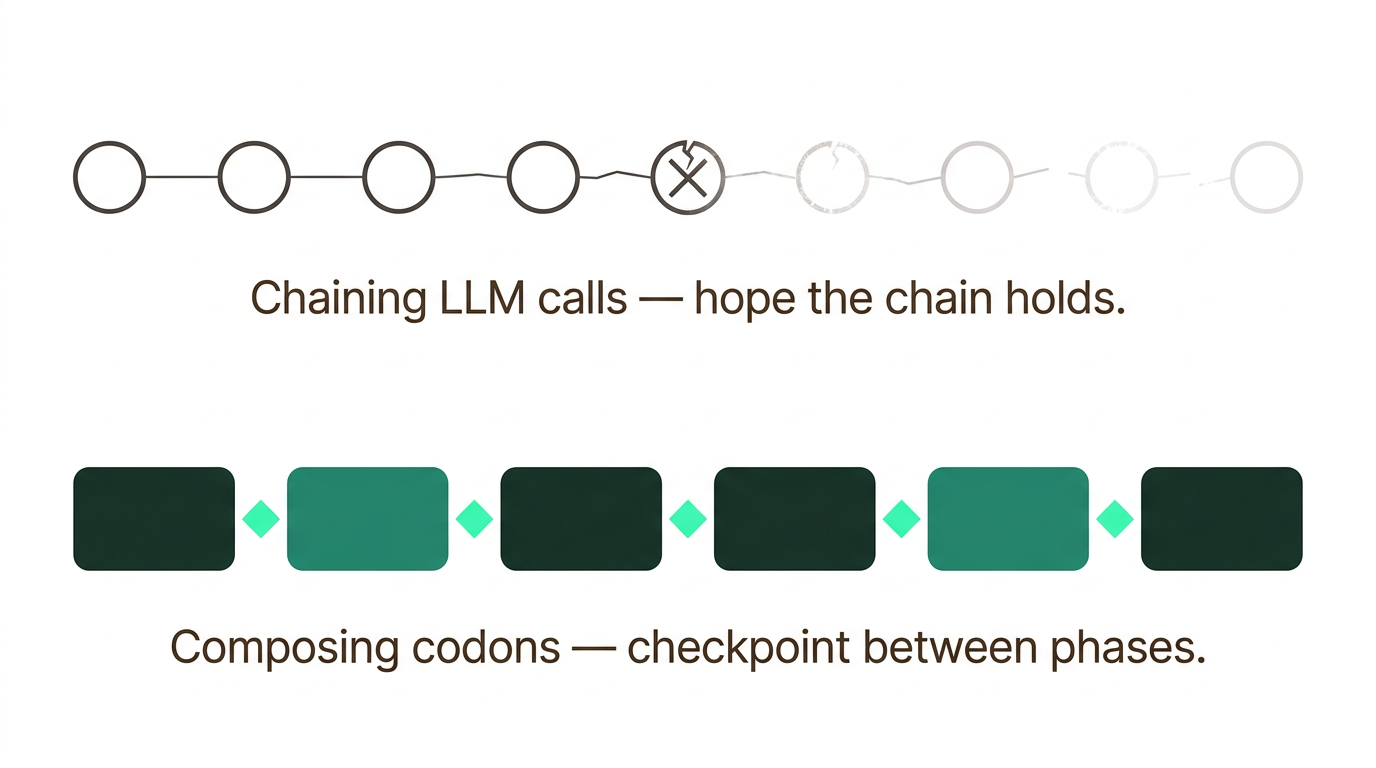
Most agent tooling today thinks in terms of LLM calls. Call, response, next block. You measure success per call. You test individual responses. You chain them together and hope the chain holds.
But an LLM call is not where interesting work happens. Interesting work happens when a model has tools, makes decisions, corrects itself, uses what it finds. That might be a dozen tool calls or a few hundred - the model decides when it's done. This is the agentic loop, and it's a fundamentally different primitive.
When the primitive is an agentic loop instead of a single call, you stop chaining and start composing. "Analyze these files and write a report" is one unit of work, not a hundred API calls stitched together. You measure success at the level of the task, not the individual response.
This is what Hankweave does. The fundamental unit is a codon - a sealed, bounded environment for one agentic task. Inside, the agent has full autonomy: tools, files, shell access, whatever it needs. It works until it's done. When it finishes, its outputs get checkpointed. Files written. State saved.
Then the next codon starts fresh.
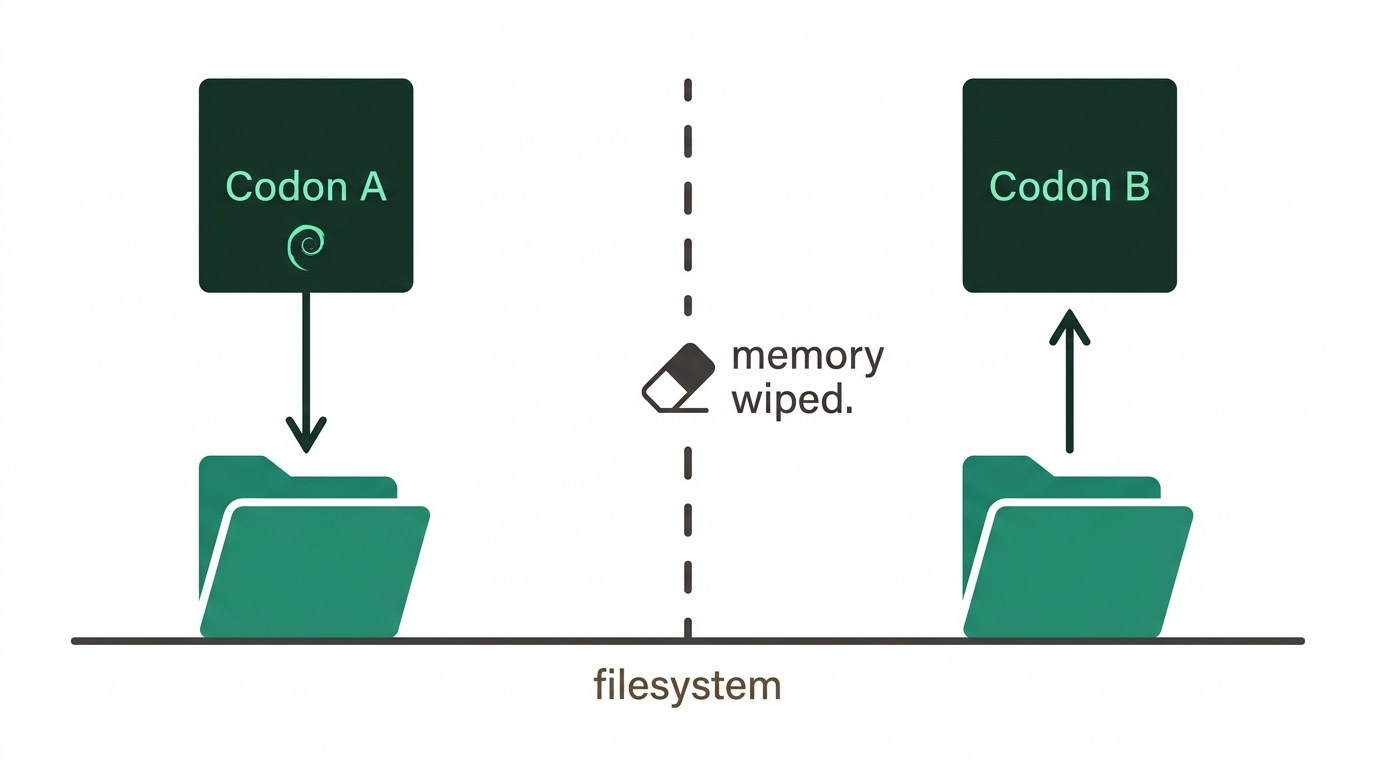
Fresh is the important word. It's also the counterintuitive one.
The natural instinct is to give each agent everything the previous one knew. Full conversation history. All the context. Let it pick up where the last left off.
What actually happens: the context grows, meaning erodes, and the agent starts confidently producing output that sounds right but isn't. It's a game of telephone played with yourself. The same thing happens to humans - ask anyone with a hundred browser tabs how clearly they're thinking.
So we force the agents to forget.
At every codon boundary, the agent stops and writes down what it found - to files, explicitly. Then memory gets wiped. The next agent has no idea what conversation came before. It reads what was written down, and only that.
This means every intermediate result is visible. A human can open those files, see exactly what passed between phases, fix what's wrong. There's no hidden state shaping what happens next. The handoff is the filesystem, and the filesystem doesn't lie.
Think of the Bambu again. It doesn't calibrate once and hope the knowledge holds. It runs discrete phases - leveling, flow calibration, first layer inspection - and between each one, it verifies. Each phase builds on confirmed results from the last. The verification is the checkpoint. The checkpoint is what makes the next phase trustworthy.
There's a concept in computer science called dynamic programming: break a big problem into subproblems, solve each one, store the result, build up. The stored results are the key - you never re-derive what you've already figured out. You trust your notes, not your memory.
We've been calling our version of this agentic dynamic programming - trading compute for reliability through structured repetition and verified handoffs. The memoization table is the filesystem. The subproblems are codons. The verification at boundaries is the ritual.
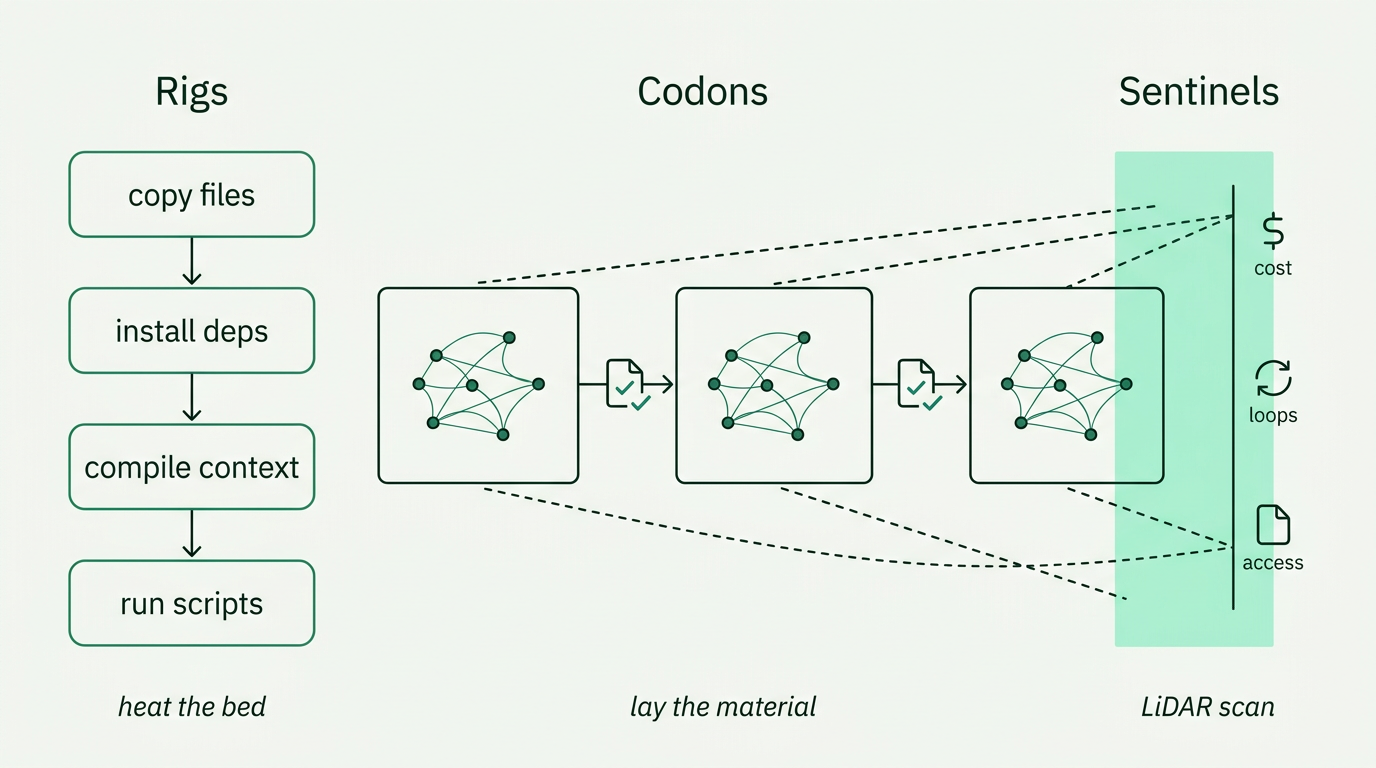
The ritual has three parts.
Rigs handle deterministic setup - the equivalent of heating the bed and cleaning the nozzle. Copy files. Install dependencies. Compile context. Run scripts. If it doesn't require judgment, it goes in a rig. When a rig fails, it fails before a single token is spent. You know immediately, and you know why.
Codons are where judgment lives - the equivalent of laying down material. The agent analyzes, decides, writes. Some codons are tightly constrained (parse this using this schema). Some are open (explore the dataset, document what you find). Both get checkpointed. Both are traceable.
Sentinels are parallel observers - the LiDAR scanning while the printer works. They watch the agent's event stream without interfering: tracking costs, catching loops, noticing when the same file gets read three times in a row. The agent doesn't know it's being watched. Sentinels don't burden the main task. They add a different set of eyes.
Three systems. Verification at every boundary. The structure that earns the trust-fall.
We built Hankweave because we had a data problem.
At Southbridge, we work with datasets that have been accumulating for decades - messy, heterogeneous, documented by different people with different conventions at different times. The kind of data where the same concept appears under four different variable names across collection cycles. Where two completely different measurements share the same name in different years. Where units change by orders of magnitude without warning.
We needed agents that could work through this for hours without losing coherence.
Every approach we tried - long conversations, massive context windows, clever summarization - broke down past a certain horizon. The agent would start strong and slowly drift. Small errors would compound until the output was plausible and wrong.
The structure we landed on - forced fresh starts, explicit file handoffs, deterministic setup, parallel observation - came from that practical need. We needed the ritual. We needed verification at every boundary. We needed a system where the hundredth run could carry forward every lesson from the runs before.
That system became Hankweave. We wrote more about the development loop - how you go from interactive exploration to frozen, reliable workflows - in CCEPL-driven development.
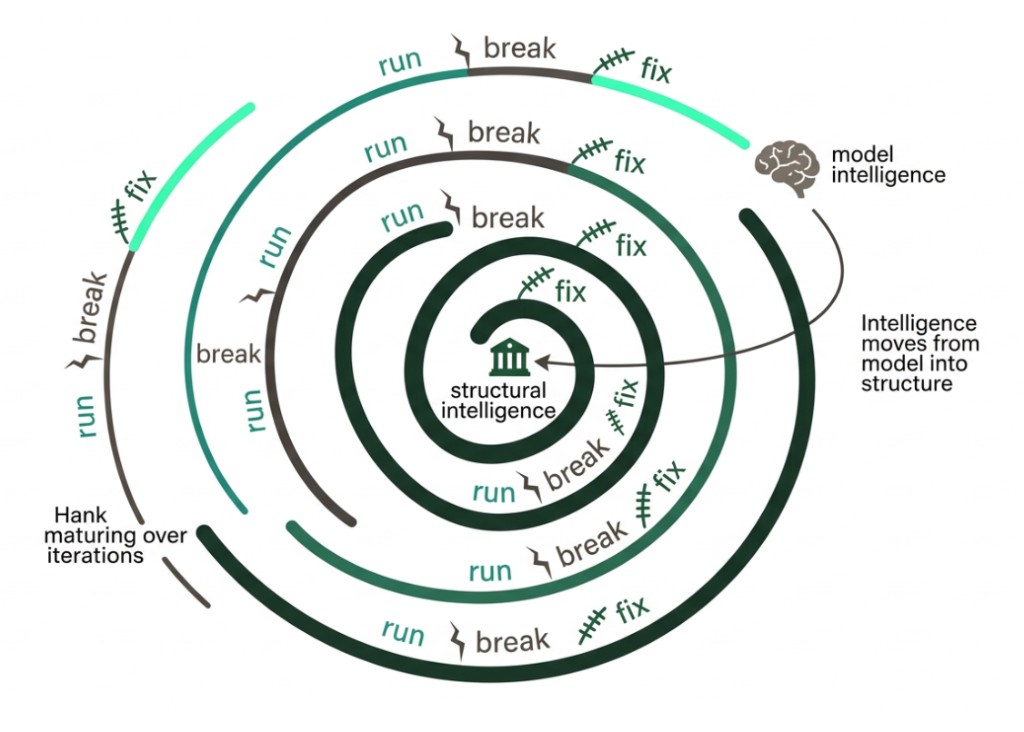
What keeps surprising us is what happens as a hank matures.
You run it. Something breaks. You fix the codon. You run it again. The prompt gets tighter. The rigs handle more of the scaffolding. Edge cases get caught and stay caught. After enough iterations, something shifts - you realize the instructions have become precise enough that a cheaper, faster model handles them fine. The intelligence moved from the model into the structure.
Failures become fixes. Fixes stay fixed. The hundredth run is more reliable than the first - not because the model improved, but because the hank did.
This is what we mean when we talk about brownfield. Every advance in AI makes it easier to start something new from scratch. But starting isn't the hard part. The hard part is what comes after: when people depend on the workflow, when edge cases accumulate, when someone who wasn't there at the beginning needs to keep it running. Better models won't tell you where fixes should live. They won't help a new teammate understand why a workflow is shaped the way it is.
A smarter printer still taps the bed.
The capability to do extraordinary things with AI is real. What's missing is the infrastructure to make it last - to take what one person figured out and give it to a team, to take what worked once and make it work reliably, to let knowledge accumulate instead of evaporating between sessions.
Hankweave is that infrastructure. Not for every task - for the ones worth repeating, worth sharing, worth getting right over time.
The ritual is the reliability.