This is the long version of a talk I gave at SuperAI Singapore on June 10, 2026. It's the version of "agents are hires, not tools" I've been carrying around in my head for a while, plus the question I used to worry about getting and finally have an answer to: why not wait?


AI adoption is finally here. We're all spending untold amounts of money. But we've now got a new problem, and a question that hasn't gone away.

I run Southbridge, where we build data agents for all sorts of things. Mining healthcare datasets. Connecting financial information. Ingest problems. Migrating entire databases in production. Especially work that happens in the critical path.
Today I want to talk about the two big questions in AI right now, one spoken and one unspoken, and why the answers matter to using AI as an organisation, and not just as a collection of individuals.
This talk was submitted a month ago, which in AI time is four or five paradigms ago. Originally, it was going to be about how AI being introduced into an org should be treated more like a hire than a tool, about the problems we were seeing companies encounter and how to fix them with better data. We're still going to talk about that, but this time we dig a little deeper, away from the symptoms (high spend, brittleness) and into the specific questions at the very root of the problems.
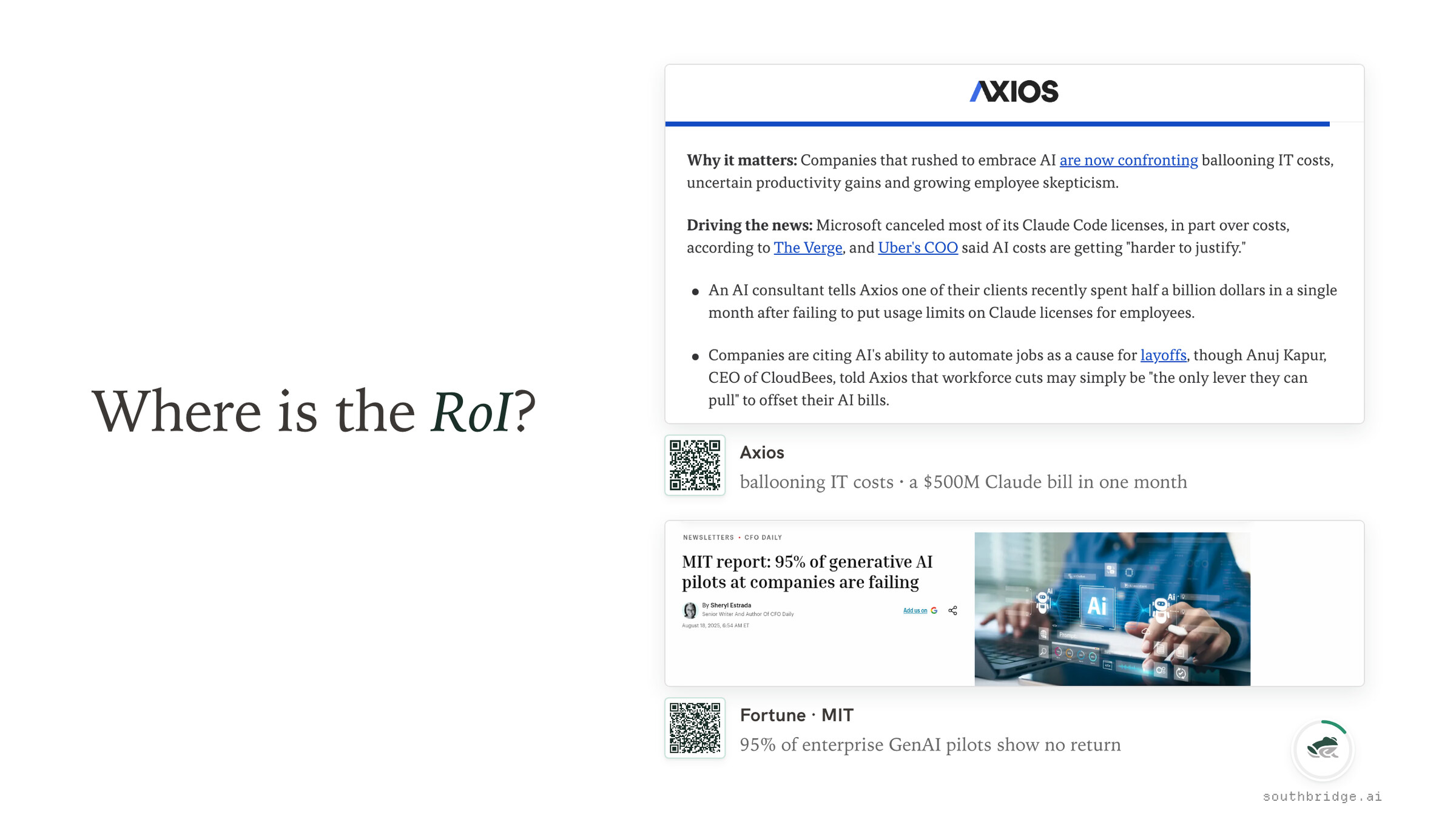
The first, the loudest but I'd say less important, question is: where is the RoI?
When people ask where the return is, or how to improve it, what they're really saying underneath is: I'm here. I showed up. I'm listening. I'm willing to spend. But I need to connect this to my core business to justify this return.
The headlines are loud about both ends of the same picture. Axios is writing about ballooning IT costs and half-a-billion-dollar Claude bills in single months,... and MIT's NANDA report has the famous number: 95% of enterprise GenAI pilots show no return....
Short answer: the return is there, but it's leaking away to an increasing river of slop and wasted spend, repeated work, and review load. People are being forced to be the persistence layer for AI models, when it should be the other way around.

The second is the question I used to worry about getting, the reason adoption looks the way it does today: why not wait?
For the first time ever, there's an answer that applies across the board. And you can see it if you look at what's happening.

AI adoption is finally here. But it's happening through bottom-up budgets, reserved for tooling. Maxed-out credit cards, 500K bills, very little top-down control, except "let's buy the tools you think will help."
For what it's worth, AI adoption is finally here. But what's actually being adopted are variations on the same theme of coding agent. Read from repo, write to repo. Repurposed for all sorts of things.
And it's not happening in the critical path. It's happening through what we've come to call online agents: things that require a human being in front of them at all times, usually your best people. Even today, most of the use I'm seeing is individual, which means that smaller, newer companies benefit more. We can afford to rebuild, and keep rebuilding, our companies as things change.
Why is this happening?


Agents are being treated as tools. Tools to do small, specific tasks, which they kind of can. But models aren't tools in the traditional sense, like a VLOOKUP or a SUM. They are non-deterministic, complex things. They are often synthetic hires that need onboarding, scoping, supervision and correction, to be taught the way your company works before they can be trusted.
And we now have 50,000 copies of them being dropped into your organisations. (Pick your image: paratroopers behind enemy lines, or the warehouse of Buzz Lightyears in Toy Story 2.)
It gets worse when they're given little context. They inject their own preferences into the work, and they make their own judgement calls. Judgement calls is the term we use internally for decisions that could have gone either way, and the deciding factor was experience.
This is why most websites now sound like Opus. Most videos too. And if I'd gone to Opus with my ideas and asked it to draft this talk, I'd sound like Opus. Despite the ideas, the work, and the expertise being mine. I went to DeepSeek instead.
Through the course of a single day in an org, hundreds of judgement calls, large and small, are being made across the company. With models now in the loop for something as simple as telling the time, how long before organisational rot seeps in? How long before it becomes impossible to tell what was AI and what was the right call?
The longer-form version of all of this is Antibrittle Agents.

So it's 50 First Chats. Where the AI is Drew Barrymore.
People showing up to these things and just talking to their agent and trying to get something done, over and over and over again. Reliability doesn't actually improve until you start fixing things that can stay fixed across the work. With low reliability, all work then needs to be reviewed forever, which costs more time than you save.
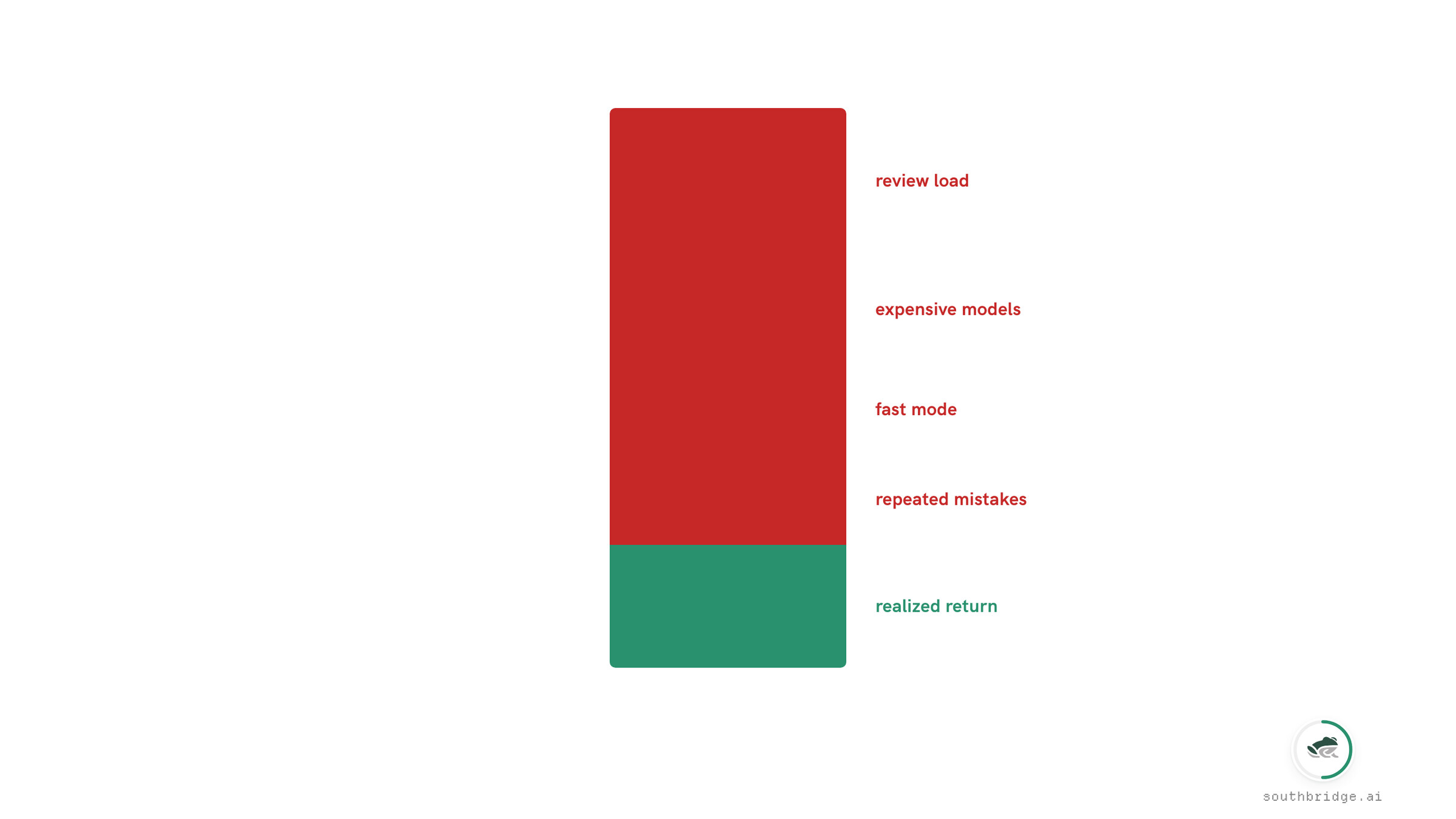

That is where the ROI is going. It's present, but it's being buried.
Review load. Token costs are high, because doing things well with very little context requires the best models that money can buy. Fast mode: having only online tooling, with latency-sensitive humans on the other side, on paid time, means you need to pay for the most expensive inference. Repeated mistakes, every conversation starting over.
The return, on the other hand, is actually happening. If you isolate the best spots of your company with the right person-agent-task fit, the right person using an agent with the right context on the right tasks, you'll see this massive 10x, or 100x, spike in productivity.
What if you could transfer that over to anywhere else the work was being done? What if you could prevent that repeated frustration with a self-improving surface where organisational knowledge, not just documents and data but real information on how to do something, could accumulate?
But let's touch the largest question in the room first.

Why not wait?
AI has been changing so fast that even forgetting to adopt it, just going to sleep for three months and waking up, you come back to better, cheaper, simpler versions. You could have experimented with Open Interpreter, fallen asleep for six months, and woken up to Claude Code. You could have fallen asleep again and woken up to Claude Cowork in three months.
On the other hand, early adopters don't always have the best time. One of the most interesting things about San Francisco, where we're partly based, to me is how bad the wifi is. A city with self-driving cars, where networking itself was invented, has some of the worst connectivity of any major city. Why? Because they were early adopters to a new piece of technology, called the internet.
When top-down change is expensive, adopting too early can mean having more to rip out. This question hangs over so many discussions. Because unless you're a high-frequency trading firm where the other guy with better tech is going to bankrupt you in seconds, why not wait?
In modern AI, from RAG to function calls to loops to harness engineering, the paradigm itself changes so often. You would be forgiven for looking at Opus 4.5, fourth-and-a-halfth of its name, and thinking, that's an iPhone 4.
But no. Opus 4.5, combined with Claude Code, is at best the iPhone 1S of a completely new kind of AI system.
So, why not wait?
If you're eagle-eared, you might have noticed I answered it already. It's because AI tooling is here, it's addictive, and it does improve productivity. And we're all using it, whether we're allowed to or not. AI is not just tooling. It's also a behaviour.

This accelerating behaviour has waste products that are beginning to accumulate, like London in 1854.... AI-driven judgement calls. Slop-ridden documentation and knowledge. Fragmented processes that are vendor-dependent in a fast-moving industry. There's a cost to allowing tooling to percolate through your org when that tooling has a mind of its own.
You're also paying this heavy organisational tax that prevents the ROI from showing up, because your people are becoming the AI's persistence layer. Having to remember how to prompt the AI and tell the AI something else. Manually having to text each other and pass files around so the agents work better. Surely it needs to be the other way around. As Canada Bill Jones is supposed to have said about poker tables: if you look around and you can't find the persistence layer, you are the persistence layer.
There's a Peto's-paradox version of all this too.... The Million Women Study found taller people get cancer about 16% more often per 10 cm of additional height, more cells, more chances for something to go wrong. The larger the organisation, the more cells in the system, the more places for the silent rebuild to happen.
Which is the real hot take: the larger and older you are as an organisation, the less you can afford to wait. Because you have functional processes and systems that are slowly but surely getting pulled down, rebuilt and readjusted very silently.
I'm glad you asked.
The problem is that most of the things inside an old system, be it an organisation, software, or government, can't be re-derived from first principles or built from scratch. They're the result of years, sometimes tens or hundreds of years, of repeatedly improving things, solving problems, and sometimes just "this is how it's been done."
Think of taking the smartest person you know and dropping them into your company with little context. What do they still need to be told?
The second part is that intelligence is just one axis, kind of like processing power. The most powerful computer in the world is still limited without a network. In the same way that we're limited without each other, which is why we have conferences.
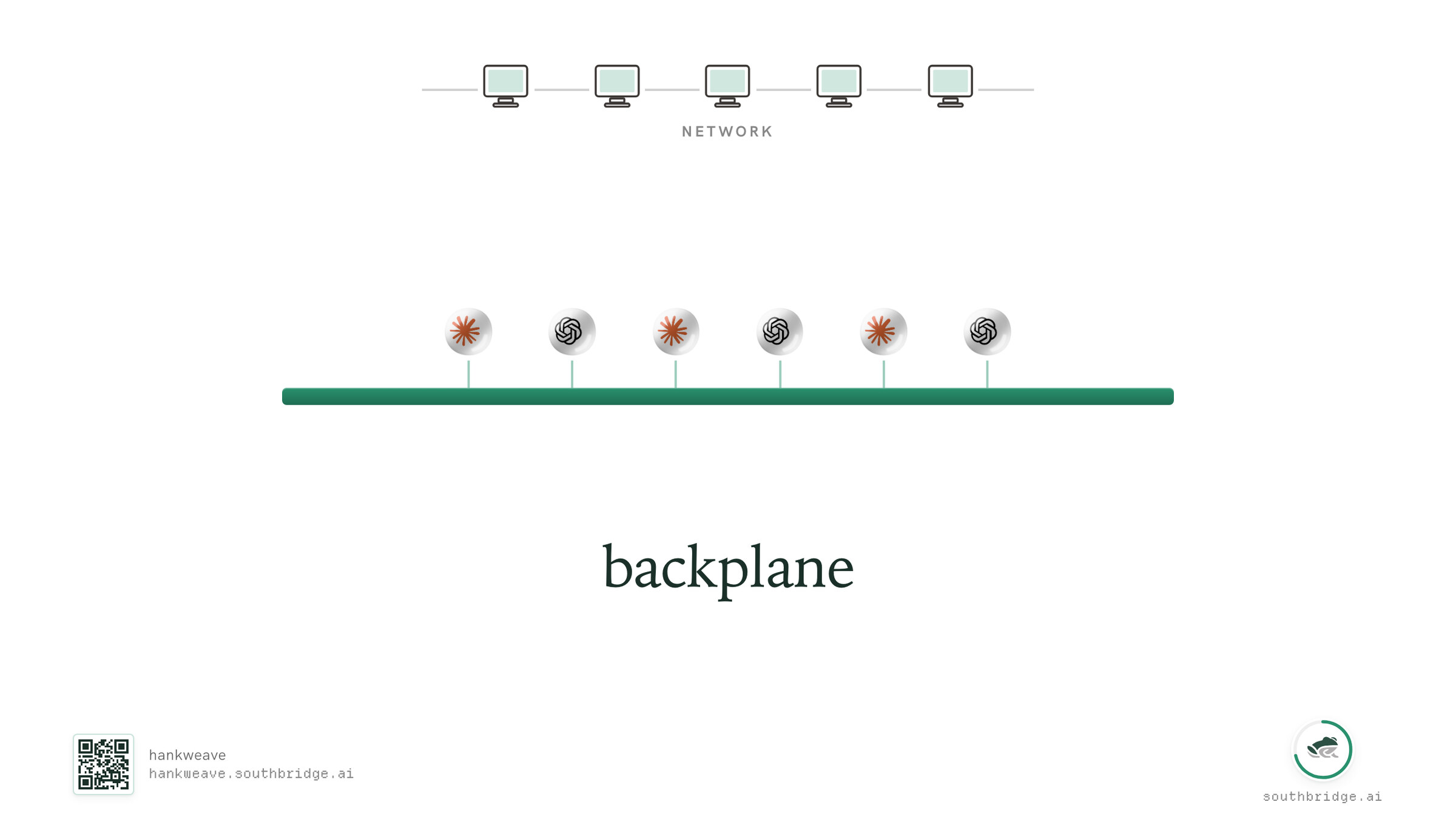
So what is that network layer in our case? At Southbridge we call that a backplane.
To stop repeating work you need something, any abstraction, where you can capture work, so that instead of do-repeat-repeat-repeat, it becomes do-reuse-improve-fix.

One of the goals we've had at Southbridge, both with our products and ourselves, has been to not make the same mistake twice. A shared surface makes that possible. Companies are familiar with runbooks. Pilots are familiar with checklists. Governments and compliance folks would be familiar with regulations.
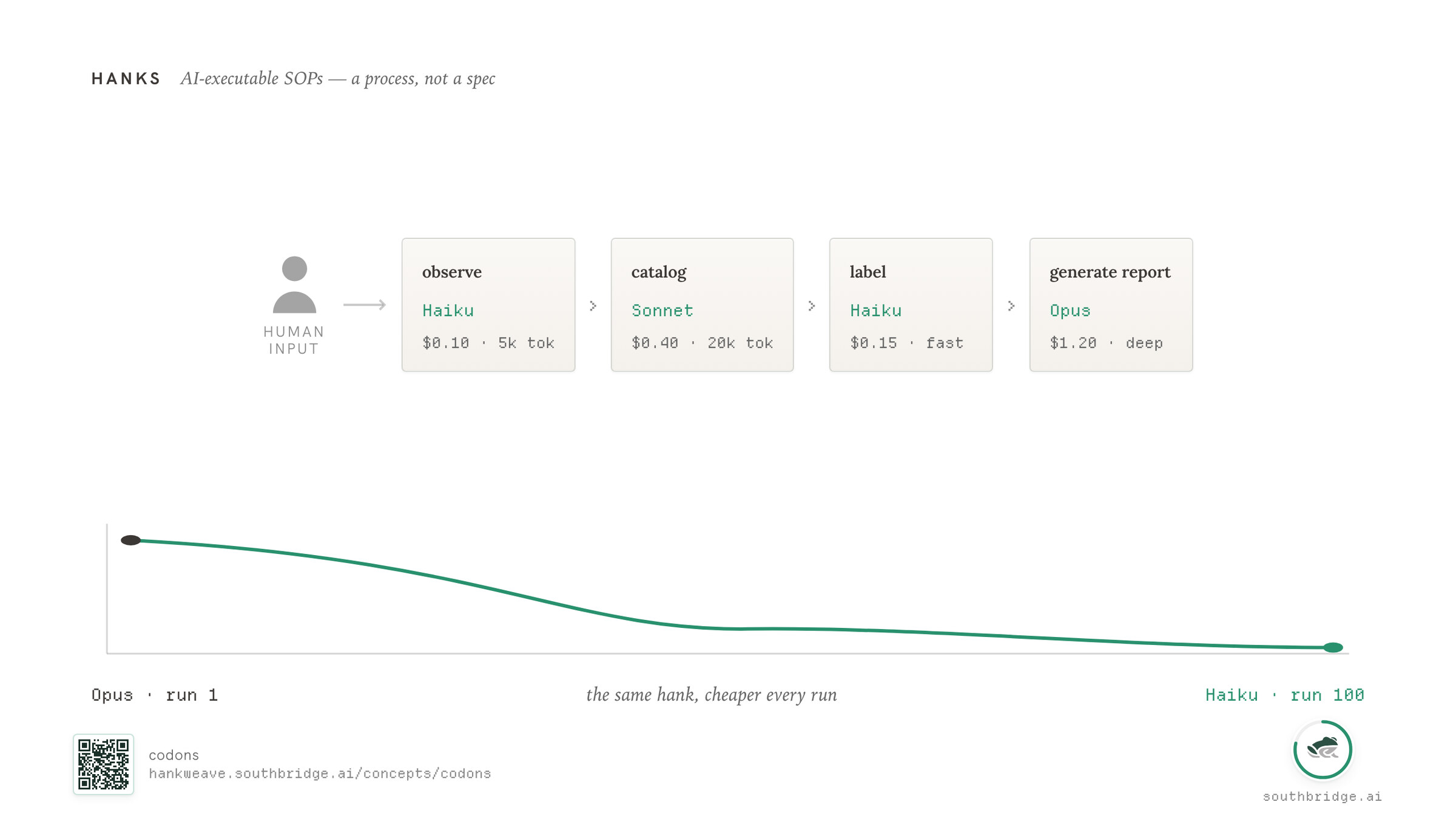
This is why we built hanks, which are AI-executable SOPs and workflows. They're better than skills because work is a process, not a spec.
We use these things internally to put down capabilities and repeated processes, and they get executed in a runtime that we built, use, and fully open-sourced recently. Think of it as a more powerful managed agents runtime.
This has been a massive unlock for us. And I recently mentioned this elsewhere: the unlock is not the abstraction, but having an abstraction. It's nice if it's an open-source declarative system that you can port your knowledge into, like Hankweave, but any abstraction works.
Having this surface to specify complex agentic work, this then this then this, and specify what you need to see at each point, has allowed agentic work at Southbridge to mature. To grow past the permanent adolescence that most systems today seem stuck in.
What do I mean by mature? As hanks and workflows improve, get reused and fixed, they become headless and offline by design. They need less human intervention or babysitting, like a hire. They almost learn, because when a mistake is made you can fix it and it doesn't happen again, like a good hire. And, unlike your best hires, they get cheaper over time. The same hank or SOP that took Opus on run 1, we've seen this many, many times, can be done on Haiku or an open-source model on run 100, because it's gotten that much more mature.
We can finally let our processes grow old, instead of staying on greenfield.
We've now deployed hanks with companies and with ourselves: for data onboarding, hygiene, cleanup tasks, business test generation, even comic books and slides. If you use our planning hank, you instantly know what I know and do when I start building a complex piece of software. We've shipped that capability. In other places, hanks have captured processes that previously took hundreds of human-hours sat at the computer, and made them repeatable, and on the path to becoming cheaper.
So those are two things we've found to be extremely successful: SOPs that AIs can use so processes can mature, and treating agents as hires so they're properly onboarded to your systems.
Writing these SOPs has been a manual process from day one. Here's me making a hank six months ago. Manual, but rewarding. Writing a hank takes thought, effort, and careful precision to include what you know.
Once it's working, fixes make things easier, but we traded the ease of greenfield for ease in legacy, brownfield operations.
Every new person to Southbridge, hire or customer, has immediately asked if models can make these hanks. The answer for me so far has just been no. Models just aren't smart enough to really understand the perspectives of the user, the builder, the models running inside of them. Moreover, what you're looking to put down is the human preference and domain expertise, not what the model thinks is right.
The answer used to be no. In the last few weeks, it has started becoming a yes.
Models under the right guidance are now smart enough to run, iterate, and improve hanks all by themselves. Additionally, we're figuring out how to use human-agent traces to capture all the useful expertise in them and turn them into SOPs.
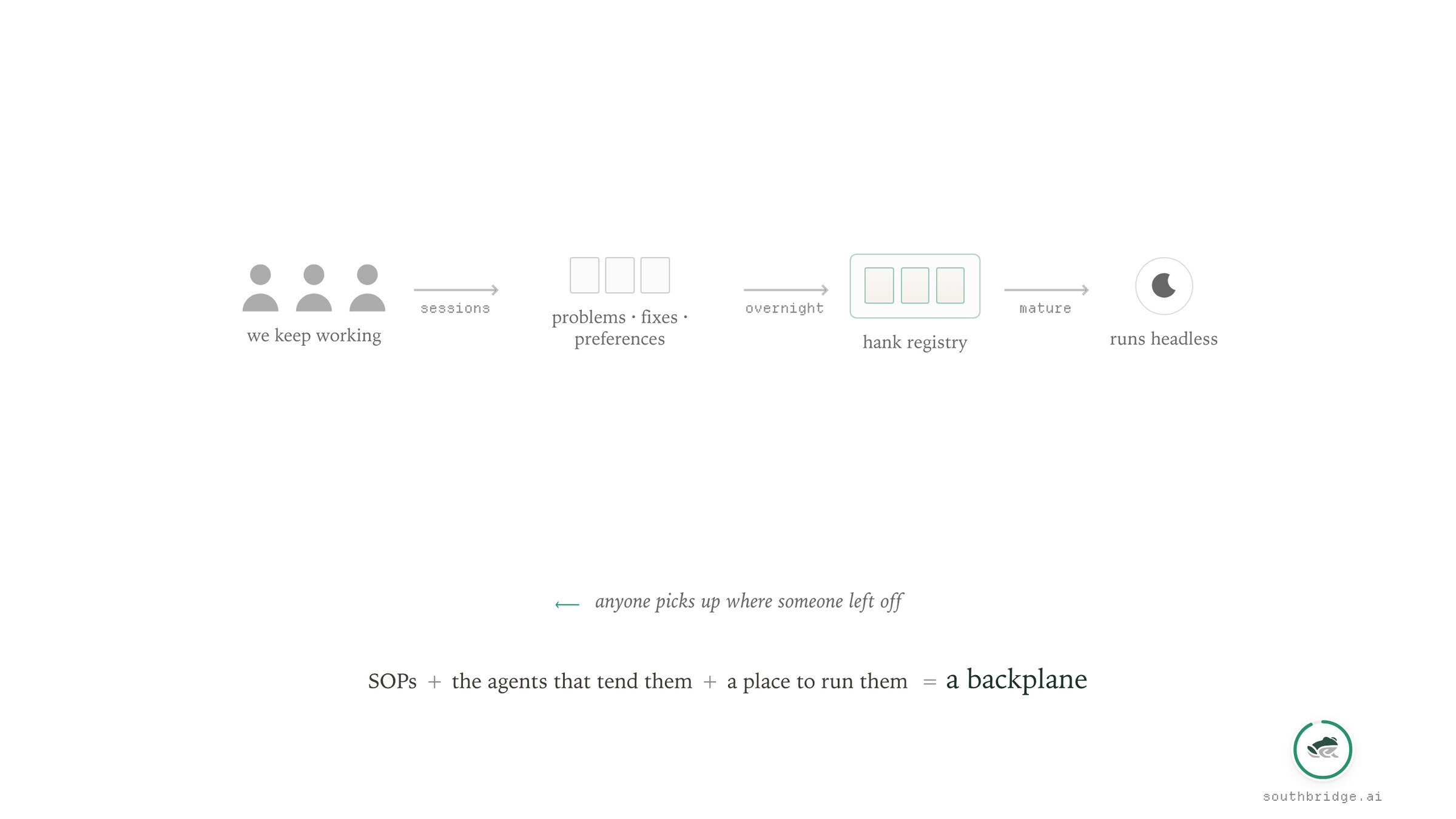
Think about it. We just carry on working as we are. We spend time on the tough tasks day to day with our agents.
The same sessions, the traces of those, contain all of the problems we encounter. Our issues with the models, the environment, specific niggles, how we fix them, our preferences, our domain knowledge.
And just armed with these sessions, headless agents can work overnight to concretise those learnings into SOPs. Those SOPs can improve over time so that future agents and humans can retrieve them from a registry, and pick up where someone else left off. So those same executables can mature and become cheaper over time, and eventually run without needing humans to relieve them and babysit them.
All of those things together, those SOPs, the agents to manage and maintain them, and the place to run them, is what we call a backplane.

The biggest thing that humans can do over AI, or nature, is learn from each other, almost instantly. A polar bear has needed thousands of years to evolve coats that help it survive. A human kid can see an adult kill a polar bear, skin it, prepare the coat and wear it, and learn that for a lifetime and pass it on.
With the right surface, an organisational backplane, we can enable the same thing for our systems. Agents can be synthetic hires that operate on that same backplane.
2027, I think, is the year we figure this out. When we move agentic work offline to run and mature independently, without interactive human input.
A surface for process knowledge is what lets us do for our systems what we already do for each other: learn once, pass it on.
If any of this resonated, the runtime we use in production is open-source at github.com/SouthBridgeAI/hankweave-runtime, and the hanks and docs live at hankweave.southbridge.ai. The companion essay on agents that don't break is Antibrittle Agents; the companion essay on why brownfield is where the work really is is No Country for Old Code. I'm @hrishioa on Twitter.