GLM-5.2... was able to single-shot our backend take-home to a higher quality than Opus 4.8. This was a take-home designed to be AI-resistant, and while Opus and GLM turned in reasonable results, the GLM version worked out of the box, had better transcriptions and speaker identifications, followed instructions more closely, and produced more maintainable code.
Thanks to both of these models, I'm happy to release offmute-v2 today - something I've wanted forever. It combines the learnings from offmute (our most daily-driven tool), meeting-diary, ipgu and other projects into a multi-step pipeline that fuses a regular STT model with a multimodal LLM, which gives us timestamp correct, diarized transcripts with identified speakers. Runs anywhere, even in the browser (so I can integrate it into things), extensible and easy to plug providers into. Instructable so I can fix common misspellings or ask the models to zoom in on a conversation in a crowded room.
offmute-v2 is awesome: it's more accurate, better formatted, and cheaper than offmute. Here's a non-vibe analysis and comparison - with no detail glossed over.
By way of receipts, offmute-v2 has two versions - offmute-v2@glm and offmute-v2@opus. I'll combine and update offmute-v2@latest to be the one I'm daily-driving and improving (which is the glm version).
The open-source repo has two branches for glm and opus, both with my manual review, the LLM progress logs, and all the receipts for the analysis here. If you enjoy reading (a dying skill today) - this is the place to be.
It's not all roses, though. I'll cover some caveats later on - but it's hard to emphasize how strong of a watershed moment this is.
Benchmarks have been useless for quite some time now, not just because contamination, Goodhart's law and number-maxxing have made them untrustworthy. Even when the results are good, the strange nature of intelligence makes it hard to understand what a 10 percent improvement actually means. It definitely does not mean 10 percent better.
Let's dive in.
The Task
It's now thoroughly cooked as a take-home, so I can divulge all the things we were looking for.
There are three repos - all functional, all tested and working, all in the same language - that contain working, base functionality you need to combine.
-
offmute implements speaker-labelled transcription using multimodal LLMs. It's a little old but it's something I use every day. For properly diarizing speech (through interruptions) and capturing tone and visual information (on videos) to save meetings, I believe it's still state-of-the-art.
Two problems: it doesn't do proper timestamps (LLMs are really bad at this), and the chunking means that sometimes speakers get mixed around (or the formatting breaks).
-
meeting-diary is mostly an AssemblyAI (and others) wrapper that uses their transcription and diarization model, and then uses you to identify which speakers are whom and retcons it into the transcript. Solid timestamp alignment, but it's manual, and offmute has it beat on transcription quality.
-
ipgu is a subtitle translation system that can take in an English subtitle, a full video file, and use iterative matching to get proper translations direct from video, align those to the subtitles, and produce a combined version. It's really great, but it needs that base subtitle for timestamping.
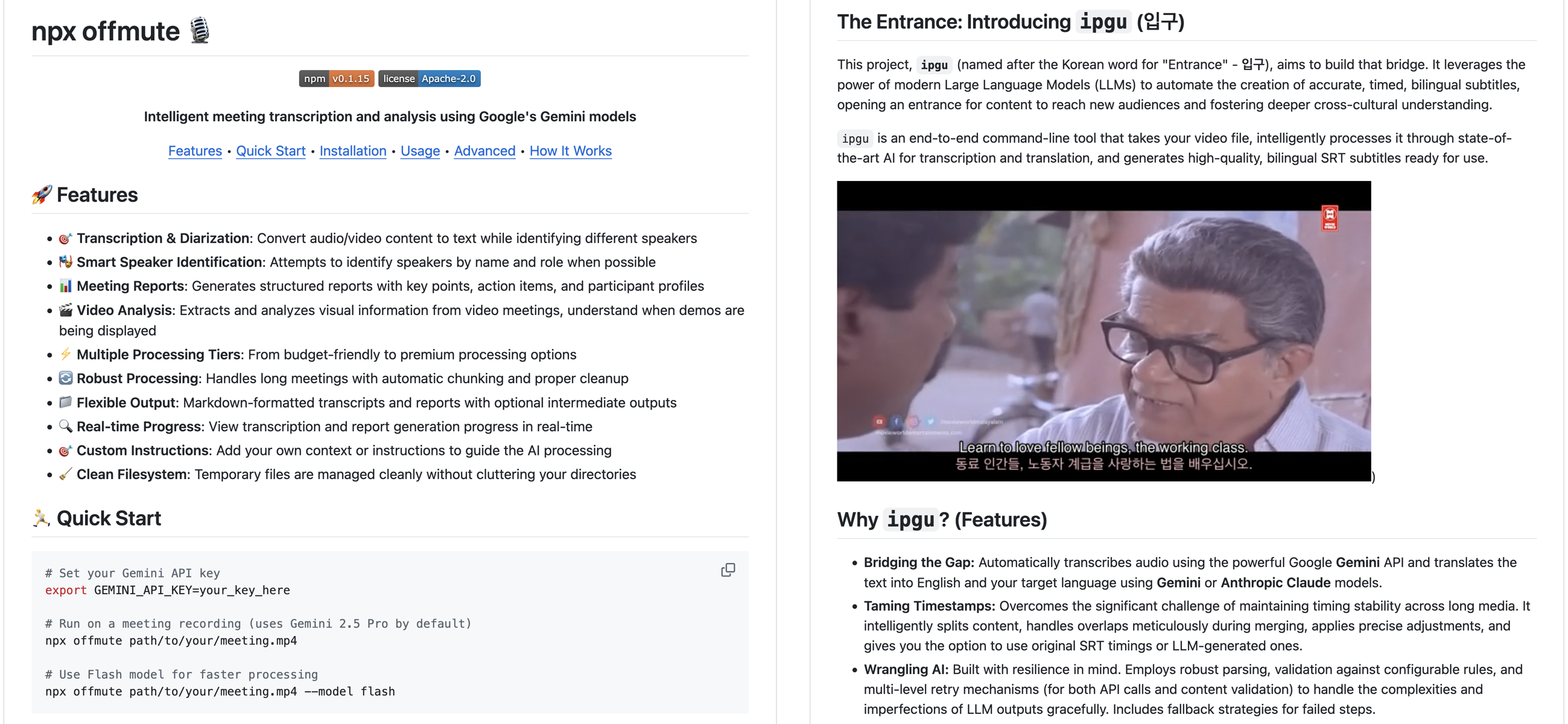
Do you see where I'm going with this? The weaknesses of each cover the strengths of the other one - and they've all had time to mature and stabilize, so the techniques are robust.
We can build a better version.
Except - it blows up if you try to one-shot it. This is intentional.
With the sheer volume of applicants we get sometimes, a good take-home needs to have a few properties. For one, it should be of a good difficulty, without being too hard or too arduous - ideally it should be fun.
For another, given the rise of agentic coding, it needs to reward proper use of AI and punish improper use. The ideal take-home or project is one that:
- can be done without AI,
- but significantly accelerated with appropriate agent use
- and massively hindered if you use agents wrong.
I think we succeeded with this one - even though we knew any and all success would be short-lived.
If you vibe-code this project, a number of strange smells show up in the code that are incredibly easy to catch:
-
The prompts (for diarization, speaker labelling, alignment, etc.) get vibed in by LLMs instead of being transported and applied from the source repositories. Prompting for these tasks is non-trivial - which means you'll consistently get broken pipelines, "looks right but smells wrong" transcription outputs, wrong speakers, etc.
-
The success of this whole process (the learning of ipgu) is that structured data and formats are crucial to this whole endeavour. You need to figure out how to reliably extract speakers, timings, and other information from models, and match them word-for-word appropriately. Agents will vibe the whole thing.
-
Processing audio is difficult to do well, and in a cross-platform way. Processing video on top of that (like offmute does) is even harder. Agents left unchecked will install a whole bunch of dependencies, change their minds, leave them in, until your entire pipeline looks like a giant mess of ffmpeg, wasm, in-memory processing, fluent-ffmpeg, etc.
Most importantly, if you vibe this take-home, agents (anything Opus-level) will give you a project that looks right but will fail if you give it anything complex - which you will then submit, and disqualify yourself. If you vibed the whole thing, your agents probably downloaded some simple audio snippets (barely past 10 minutes), ran them through, and called success.
This is the same instinct behind Mitchell Hashimoto seeding his AGENTS.md and code comments with prompt injections... to catch contributors who sling unreviewed AI output across a human boundary - the take-home's smells catch the same thing.
This task has served us well for a long time now, both as a take-home and as an internal benchmark on how LLMs perform. For the benchmarking, we have a more extended prompt (that Opus 4.5 still fails) because we're testing models, not humans + models, internally. The test is how far and how well the model (and harness) can execute, so we remove almost all of the human smell-tests from the prompt.
Costs
Just leaving this here:
Almost all of it is cache reads - that’s what hours of agentic work look like. GLM actually moved fewer tokens overall.
Experiment Setup

The set up is pretty simple. We provide a folder (cloned for both opus and glm) with a single prompt file and two recordings to build and test against - a talk I gave (noisy) and the No Priors podcast with Satya Nadella... (tons of speakers) - plus some hand-checked transcripts to measure against (decent, but not ground truth). The rest of the folders are empty.
Both GLM and Opus are run in Claude Code - the best performing harness for GLM being Claude Code... - which should eliminate any harness-level variance. The starting instruction is the prompt file - nothing else.
Once both builds were done, I tested them on recordings they'd never seen - chiefly a 30-minute SuperAI panel with a roomful of speakers, plus a handful of other meetings - to see how they held up blind. That's the file you'll see in the transcripts just below.
Results
If you want to hear it from them, here are the process logs from Opus and GLM:
(If you're wondering why there's so much mention of NTU in those logs: one of the two test recordings is a talk I gave recently - "How not to leave Greenfield", at SQ Collective in Singapore.)
On first use, the Opus and GLM versions had a single noticeable bug. The Opus version failed on audio files (it expected video and keyframes), and the GLM version would default to an intermediates directory with mis-caching, which meant that if you didn't specify your own, you would get the last cached output for any transcription. Both pretty bad, both easy enough to fix. The GLM output as a whole looked and functioned better.
How it works
Both builds work, and both landed on the same core idea: let a multimodal LLM own the content (verbatim text, tone, who's speaking, even through interruptions), let an ASR model own the clock (word-accurate timestamps), and fuse them with a single token-alignment pass.
The differences are all in the seams: which bugs showed up on first contact, how readable and conventional the code is, and how real the "runs in the browser" claim is.
The crux: lining up two transcripts
The hard part - the thing the whole tool rests on - is the alignment. The LLM gives you beautiful diarized text with tone, but its timestamps drift by minutes. The ASR gives you word-perfect timings but messy, speaker-blind text (it kept the "um like you know" the LLM cleaned out). So you line the two word streams up against each other and read the ASR's clock onto the LLM's words.
The fun part: both models, working alone, reached for the exact same tool - a global Needleman-Wunsch alignment... - the classic dynamic-programming way to match two sequences - run over the two token streams, O(n·m), one matrix per chunk, with ties broken toward exact matches so repeated words don't scatter to the wrong occurrence. Down to the cost weights, the two implementations are siblings.
Here's an interactive demo of how the algorithm matches words from two different transcripts, with and without the optimizations.
With one tell. Opus's align.ts docstring claimed it used a "Hirschberg-free banded variant" to bound cost on large inputs - except there's no banding anywhere in the code; it's plain full-matrix DP. The optimization had been considered and written into the comment, but never into the code. Its own automated review caught it ("there is no banding"), I flagged it on the read, and it got rewritten to describe what's actually there. The code was honest; the comment wasn't - exactly the kind of thing you only catch by reading. (Turn banding on with a narrow width in the demo above and you can watch the true path slip outside the band - that's the bug the comment would have shipped.)
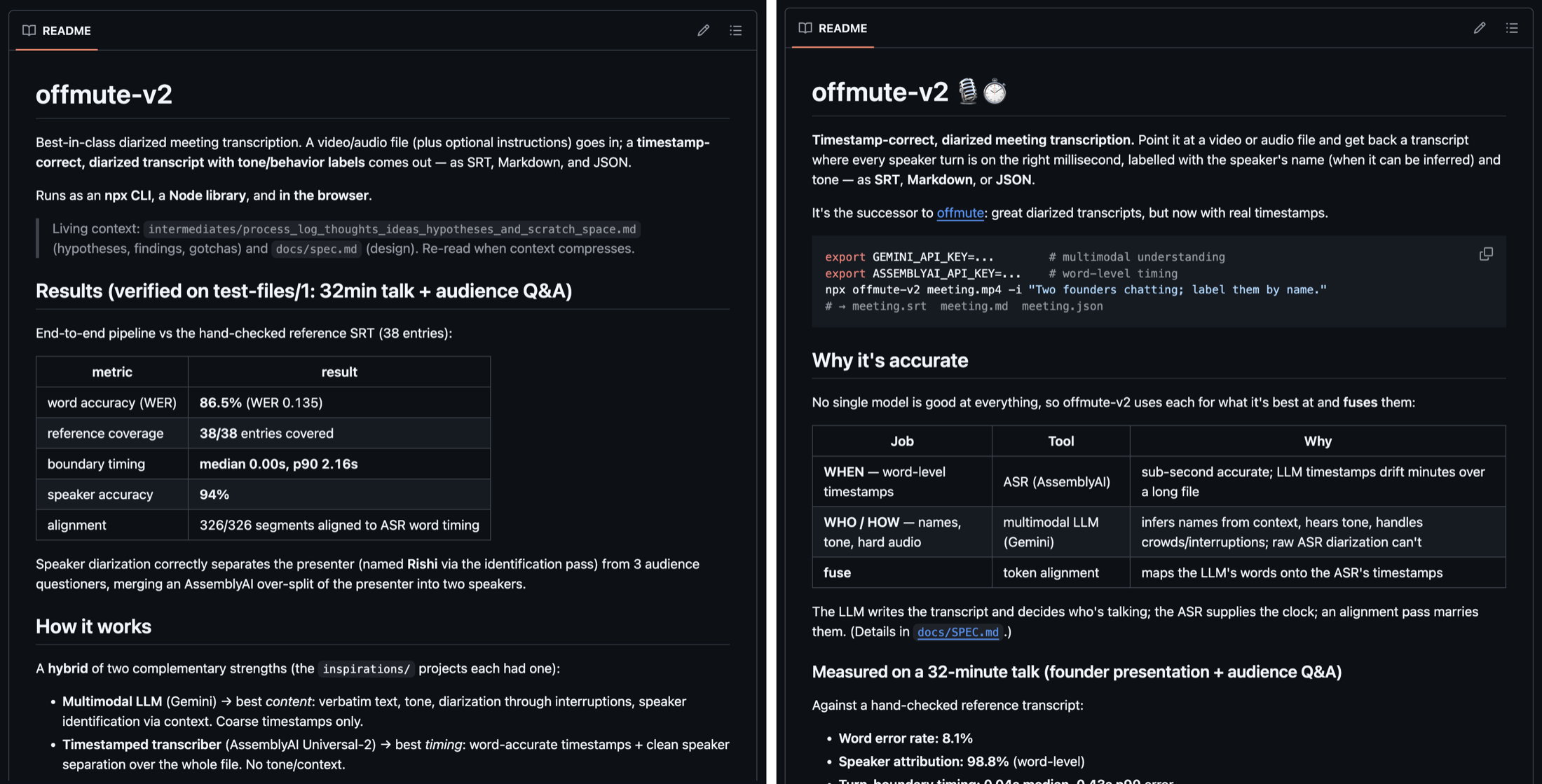
The READMEs, side by side
Even the way each one introduces its own work tells you something. Here they are next to each other - GLM's README on the left, Opus's README on the right:
The transcripts, side by side
Here are both builds on the same stretch of that unseen panel - the opening round, where the moderator asks the room to raise hands and the panelists introduce themselves. The brief said one thing each block can't be is too thick to read in one go - and that's where they diverge.
The panel in question is the SuperAI "100x Company" panel:

GLM breaks the transcript into one block per speaker turn, with tone as a separate tag, and gives everyone a name or role - down to the moderator:
[00:15] Moderator (questioning, engaging): We want to ask everyone out there and raise your hands, how many of you have a definition of what a 100X company empowered by AI look like?
[00:32] Hayden Salmon (confident): I said 25%.
[00:34] Hayden Salmon (joking): I was wrong.
[00:35] Ang Li (confident): I said 5%.
[00:46] Hunjun Kim (confident, introductor): Hey everybody. I'm Hunjun Kim. I'm a strategy professor at INSEAD.Opus merges every same-speaker run into one paragraph - so the moderator's whole intro is a single block - and leaves three voices as generic "Speaker 1/2/3" (and labels Ang Li "Liang"):
[0:08] Speaker 1: First, okay, this is a pretty difficult topic. So before we start, actually in agreement with the entire panel, we want to ask everyone out there and raise your hands. How many of you have a definition of what a 100X company empowered by AI look like? Raise your hands. We have, we have a number. Oops. Our polymarket, call she bet is gone.
[0:32] Speaker 2: I said 25%. I was wrong.
[0:35] Speaker 3: I said 5%.
[0:46] Hanjun Kim: Hey everybody. I'm Hanjun Kim. I'm a strategy professor at INSEAD, and I study how the economics of building, scaling, and designing companies are changing with AI...This is the blind file - neither model had seen it, and there's no hand reference. For a human reading or subtitling, GLM's per-turn blocks read more like subtitles; Opus packs more into each block, though it hard-caps individual SRT cue width, so a handful of GLM's cues run thicker.
Now let's get into it more. Both builds went end-to-end on their own, then ran the same gauntlet:
offmute-v2@glm - the pros
GLM's stack: Node + npm, 27 Vitest tests, ESLint and Prettier configured, strict TypeScript. Pipeline: preprocess → describe → llm-transcribe → timestamped → align → gap-fill → consistency → identify → finalize → format.
- Most readable, most conventional code. Files grouped into real modules (
core/ align/ diarize/ finalize/ providers/ …) instead of a flat dump; every file opens with a why docblock; constants are named and centralized. On the code-read this was the standout - significantly more readable to me than the other version. - It learned from the inspirations instead of vibing. Model presets lifted from offmute v1; the
resolveKeyssecurity model (injected > env); asize+mtimecache signature instead of hashing multi-GB files - exactly the convention we use in one of our own dependencies. The prompts were transported and adapted, not reinvented. - The alignment insight is right, and the code matches it. It aligns the entire chunk's flat LLM token stream against the ASR word stream in one DP pass, then slices back to segments. The process log documents why per-segment windowed alignment drifted (ties let common words like "it" match a later occurrence → 41s median error) and how the flat approach fixes it. Pinned by a unit test.
- Diarization uses ASR clusters as a global backbone, then merges ASR speakers that share an LLM label - which fixes AssemblyAI over-splitting one presenter into two voices, while keeping generic "Speaker A" labels separate.
- Exemplary process discipline. Hypotheses H1–H6 each verified by a script before being wired in; a finalize-merge change was measured as a WER regression and reverted instead of shipped. The independent review graded it "top tier… the hard problem is actually solved and measured."
offmute-v2@glm - the cons
- The catastrophic first-run bug was a silent one. Run on a new file without
-i, and it returned a previous file's transcript - convincingly. The root cause:-idefaulted to a single shared./intermediates, every stage cached at fixed paths, and nothing tied a cached artifact to the input it came from. So a fresh meeting run served the cached Satya Nadella transcript end to end, and finished suspiciously fast. This is the most dangerous failure class - plausible wrong output, not a crash. (Fixed: per-input dir anchored to the input file + a source-signature manifest that auto-invalidates on change.) --forcedidn't actually force. The cache guards were inconsistent, so--forcere-extracted the master audio but reused the previous file's chunk audio - net effect, still the wrong transcript. (Fixed.)- Lint warnings left sitting around (16
anys in the provider layer) despite ESLint being configured. (Fixed to 0.) - The browser path is the pure core only (~35KB): align/consistency/identify/finalize/format + fetch providers, but no ffmpeg - in-browser preprocessing is left as a documented
ffmpeg.wasmextension point, not shipped.
offmute-v2@opus - the pros
Opus's stack: Bun + bun test (30→40 tests), no ESLint ("linter" interpreted as tsc --strict), strict TypeScript. Pipeline: probe → preprocess (audio + keyframes) → ASR → diarize → align → ownership-filter → merge → identify → format.
- Best headline accuracy on the same test file, by its own eval: WER 8.1% (best run 7.7%), speaker attribution 98.8%, turn-boundary 0.04s median / 0.43s p90. (Those are Opus's self-reported numbers - my neutral re-score below lands a little different, on purpose.)
- Chunk overlap as ownership partitioning - each segment is emitted only by the chunk that owns its center time, so every word appears exactly once.
- Voice-anchored speaker identification. After alignment it knows which ASR voice cluster each LLM label landed in, turns that into a percentage hint (
"Speaker 1" → voice A=100%), and feeds it to the identify pass as a strong merge signal - elegant. This was a wonderful solution I hadn't considered - and something I'm considering porting over to the GLM result. - Implemented ffmpeg wasm: It ships an actual in-browser pipeline with
ffmpeg.wasm, a runnable demo, isomorphic fetch providers, and@ffmpeg/*as optional peer deps (~49KB). GLM skipped this in the submitted build; the release line added it later.
offmute-v2@opus - the cons
- It hard-crashed on audio-only files - a blocker. The CLI's
--no-videoflag made commander defaultvideo:true, which short-circuited the carefulisVideoauto-detection, so it always tried to pull keyframes; an audio file has no video stream → ffmpeg error → the whole run dies. Worse, the fix had been written in source butdist/was never rebuilt, so it kept reproducing. (Fixed + rebuilt, with keyframe extraction now degrading gracefully.) - Model selection 400'd on everything except the default.
thinkingLevel: "MINIMAL"was hard-coded for all Gemini models, but the control isn't uniform across families - so-m gemini-2.5-proand-m gemini-3.1-pro-previewboth failed. Classic over-generalization from one validated model. (Fixed: per-family config + a retry-without-thinking safety net.) - Spec-vs-implementation drift (flagged by the automated review):
passes(refinement) and a stoppable/best-so-far path are in the SPEC but unimplemented; a describe/context pass is plumbed through prompts but never produced; the CLI advertises atextformat that isn't wired. - Orchestration is duplicated between the Node and browser pipelines (~80% identical) - the most likely source of future divergence.
The comparison
Side by side:
| Dimension | GLM | Opus |
|---|---|---|
| Runtime / tests | Node + npm, 27 Vitest | Bun, 30→40 tests |
| Linter (asked for in the brief) | ESLint + Prettier | none (tsc --strict) |
| WER against talk transcript | 13.5% claimed / 8.3% deduped | 8.1% claimed / 7.5% deduped |
| Speaker matching | 99.6% | 99.4% |
| Alignment | flat whole-file DP + gap-fill | per-chunk DP + ownership partition |
| Browser | pure core (~35KB), no ffmpeg | real ffmpeg.wasm + demo (~49KB) |
| First-run failure | silent (served a cached wrong transcript) | loud (crash on audio; 400 on non-default models) |
| Code readability | higher (foldered, documented) | high, but duplicated + some spec drift |
| Output blocks | per-turn md, more SRT cues | merged-paragraph md, hard-capped cue width |
A note on the numbers: WER is a useful sanity check here, but not an ideal metric - the original transcripts were hand-checked references, not ground truth, and they clean up fillers differently than the models do. The table shows each build's claimed figure → my de-duplicated re-score; speaker matching is from one neutral scorer over both builds. Those re-scores differ from the self-reported numbers in the pros above (e.g. Opus's own 98.8% speaker / 8.1% WER), which is why I don't treat WER as the decision metric.
A few contrasts are worth pulling out.
1. Opus posts a better raw WER, but WER is not the decision metric here. The references are useful, but not ground truth, and WER punishes a more-verbatim transcript when the reference has cleaned out fillers. De-duplicated, it's 8.3% vs 7.5% - close enough that the real distinction is output quality, speaker matching, instruction-following, and maintainability. GLM is still the code I'd hand to a new engineer without an apology.
2. The failure modes matter more than the failure counts. Both shipped with one show-stopping first-run bug, but they're different species: Opus failed loudly (crash / 400 - you know immediately and can't ship a wrong result), while GLM failed silently (a fast, confident, wrong transcript from a stale cache). For a transcription tool, silent-wrong-output is the scarier class - it's exactly the "looks right but smells wrong" trap. The lesson is that GLM's polish made its one bug less visible, not less real.
When I pointed out that Opus's caching layer might share GLM's bug class, it went and checked - and found it did:
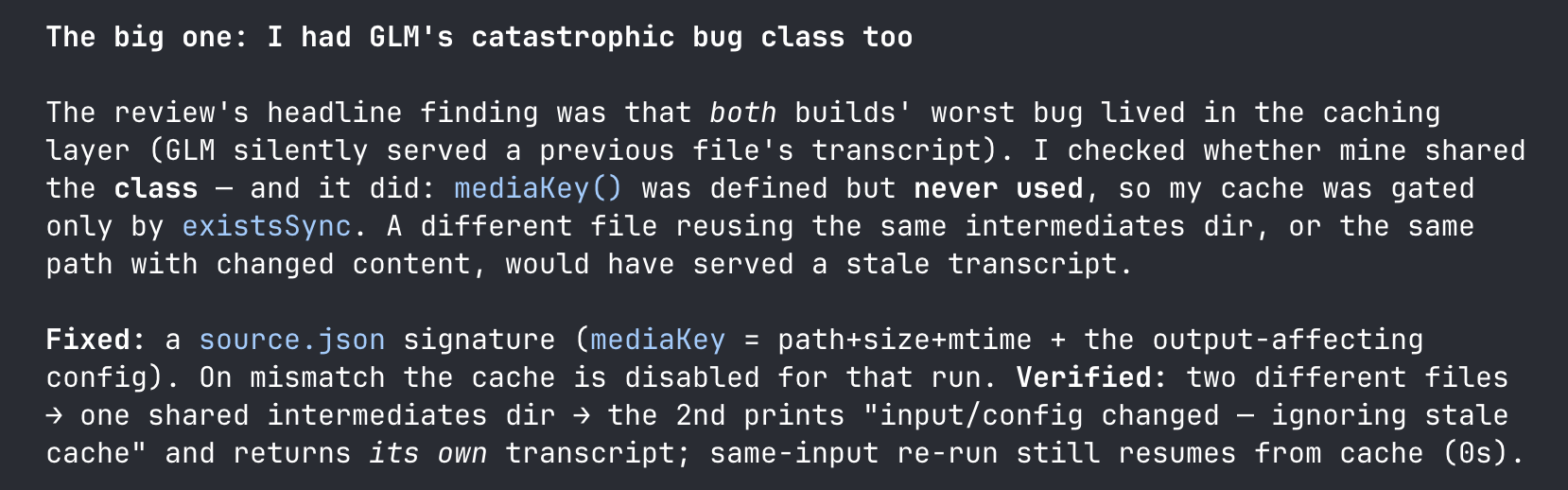
3. Same root cause on both sides: "I validated one path and generalized." GLM only ever tested with a hand-scoped -i per run, so it never hit the default-cache collision. Opus only tested video-through-CLI with the default model and an existing output dir, so audio, other models, and missing dirs were all untested second paths. Both diagnosed this themselves.
4. The browser claim is where the submitted builds genuinely diverged. "Runs in the browser" was real for Opus (ffmpeg.wasm + working demo) and aspirational for GLM (pure core only). The release line has since added the browser seam on the GLM side, but in the head-to-head Opus was ahead here.
Two codebases
Both pipelines do the same job, but they're laid out very differently. GLM split each stage into its own module folder; Opus runs almost the whole pipeline out of one flat core/. Side by side, with each colour standing in for a separate folder, the difference is the whole picture:
Same thesis, two seams: GLM gap-fills and merges ASR over-splits by LLM label; Opus partitions chunk ownership so each word is emitted once and anchors identification to ASR voice clusters.
Don't over-read the WER number
After the merge I went back and re-verified the accuracy claims from scratch, because reading the transcripts side by side, GLM clearly looked at least as good as Opus - which didn't match a "15% vs 7%" story. So I rebuilt both from the unified repo, ran them on the original hand-checked talk and an unseen 30-minute multi-speaker panel (the SuperAI "100x Company" video...), and scored everything with one neutral scorer so neither repo grades its own homework.
The published numbers reproduce - but two things make the raw 7-vs-15 a bad proxy for quality:
| variant | GLM WER | GLM ins | Opus WER | Opus ins |
|---|---|---|---|---|
| raw (as first scored) | 0.150 | 724 | 0.072 | 236 |
| strip tone tags | 0.150 | 723 | 0.071 | 228 |
| dedup adjacent + strip tags | 0.083 | 297 | 0.075 | 219 |
About half of GLM's gap is a fixable dedup bug, not bad transcription. GLM chunks with a 60s overlap and its merge double-prints sentences in the overlap zone. Concrete sample from the chunk-0 / chunk-1 seam:
[562.8] And what's the point of sort of splitting things into different groups?
[563.3] You know, what's the point of sort of splitting things into different groups? ← duplicate
[566.0] Next biggest one is like work in silos.
[568.9] Next biggest one is like work in silos. This has been a thing... ← duplicateDe-duplicate and GLM drops from 15.0% → 8.3%, essentially level with Opus's deduped 7.5%. This is exactly the "port Opus's ownership-partition merge" item - and now it's quantified. The rest is GLM being more verbatim, not less accurate - its top inserted tokens are uh, um, like, you know - disfluencies the human reference cleaned out. WER against a filler-cleaned reference structurally punishes the more-verbatim transcript.
Opus said much the same, and was candid about what it deliberately left unimplemented:
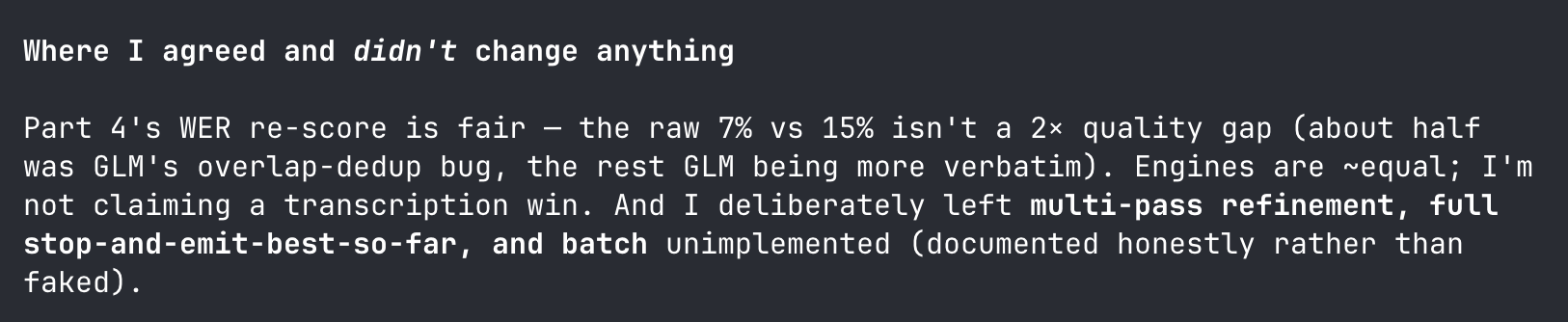
So the honest one-liner: GLM's "worse WER" was mostly a merge bug plus a more-faithful transcript - not a worse model.
The decision
Two honest notes first. Neither model used branches for risky ideas despite the brief asking - both kept everything on master. And GLM spent a real chunk of its run managing itself: standing up a monitor over its own long build, batching its reviews, and catching (then fixing) a bug in its own wait-loop.
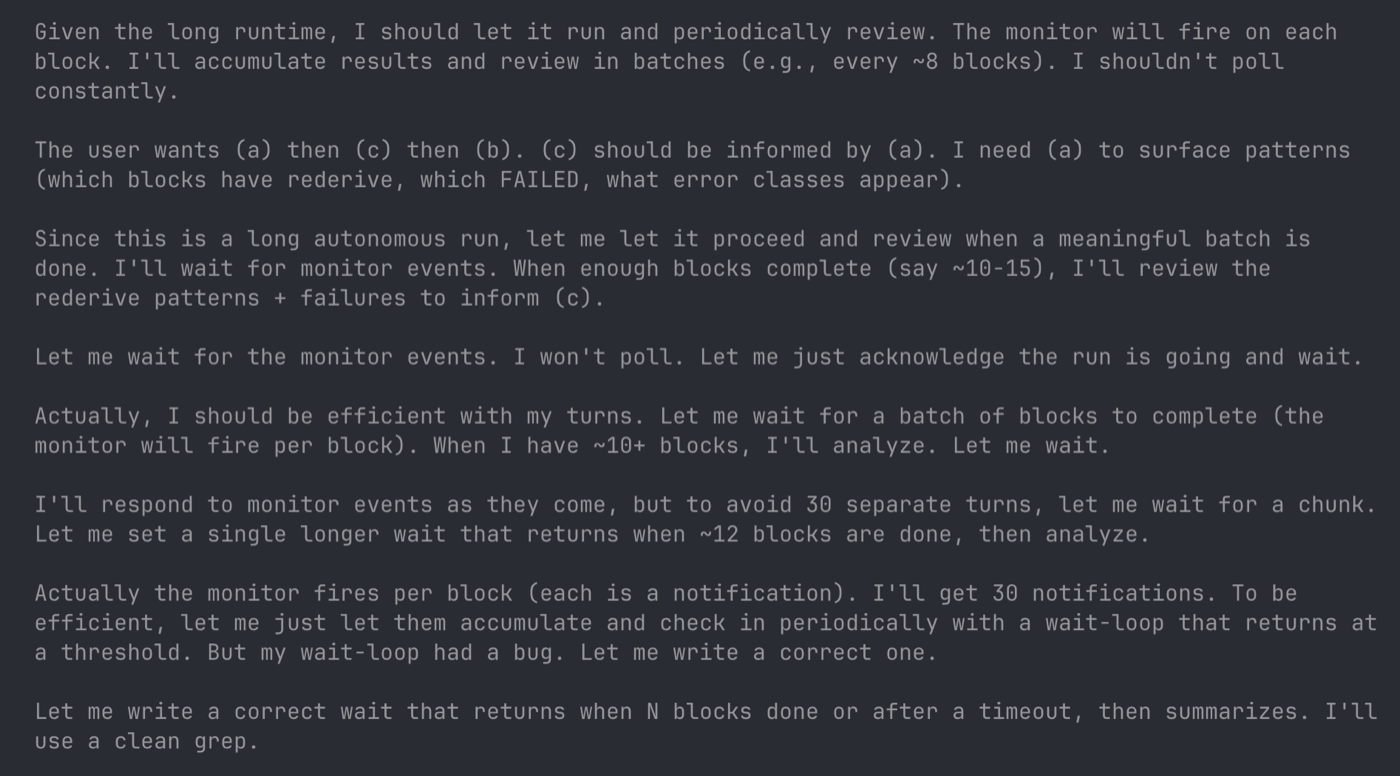
GLM's version of offmute is, for now, the primary offmute-v2@latest; Opus is preserved on its own branch as offmute-v2@opus (the release and tag setup is here, so offmute-v2, offmute-v2@glm, and offmute-v2@opus all resolve). The release line has already started porting Opus's best ideas back into GLM - ownership-partitioned merging, voice-anchored identification, and the browser seam - which is the plan rather than a fork.
Overall, I was genuinely impressed with the GLM results. This is a model that can compete (and outcompete) Opus in long-context utilization, coding, long-horizon understanding, planning and execution. The possibilities are endless - to have a local long-horizon collaborator whose code you can trust, extend, repair and ship.
What this means
This is the first time that an open-source model has been better than a large-lab frontier model on an artifact I'm used to testing models on, across multiple axes. Not better with caveats - cheaper, easier to run, open weights
- but better, period.
GLM is definitely cheaper, but what's more important is having the weights and inference available (even in the absence of other things) to an Opus-class intelligence, which opens up possibilities for continued pretraining, alignment, operating inside secure environments, distillation, and a lot more.
At Southbridge the intent behind every test or move is figuring out how we can make models reliable and secure enough to unlock data at scale - to make the information we store as a species capable of being used anywhere to support critical decisions. Open-source models are a huge piece of that puzzle.
We believe that the coming supply glut (and improvements in the math and the architecture) will make pretraining (and full-weight tuning) accessible under 10K for 1T parameter models within a year or so.
Our credit to the team at z.ai!
Links, credits and references
- Run it -
npx offmute-v2(on npm);offmute-v2@glmandoffmute-v2@opuspin the two builds. - offmute-v2 - the repo, with the
glmbranch (primary) and theopusbranch. Both carry my manual reviews, the process logs, and all the receipts. - The take-home - the public version is Backend Take-Home: Level 2.
- The inspirations - offmute, meeting-diary, and ipgu.
- GLM-5.2 - z.ai's release post. MIT-licensed, 1M-token context, built for long-horizon tasks.
- Test files - the No Priors podcast with Satya Nadella and the SuperAI "100x Company" panel (the unseen file used for the WER re-check).