Can you use logprobs to improve direct multimodal OCR?
Short answer, we can - for OpenAI models! Not so much for Gemini. Additionally, GPT does better at lower temps, Gemini does better at higher temps, and Gemini Flash makes significantly fewer mistakes than gpt-4o.
The core problem is simple: Do model confidences correlate to accuracy in OCR?
Gemini now provides token log probabilities (along with multiple candidates) in the response through Vertex AI, so let's give it a shot.
Data
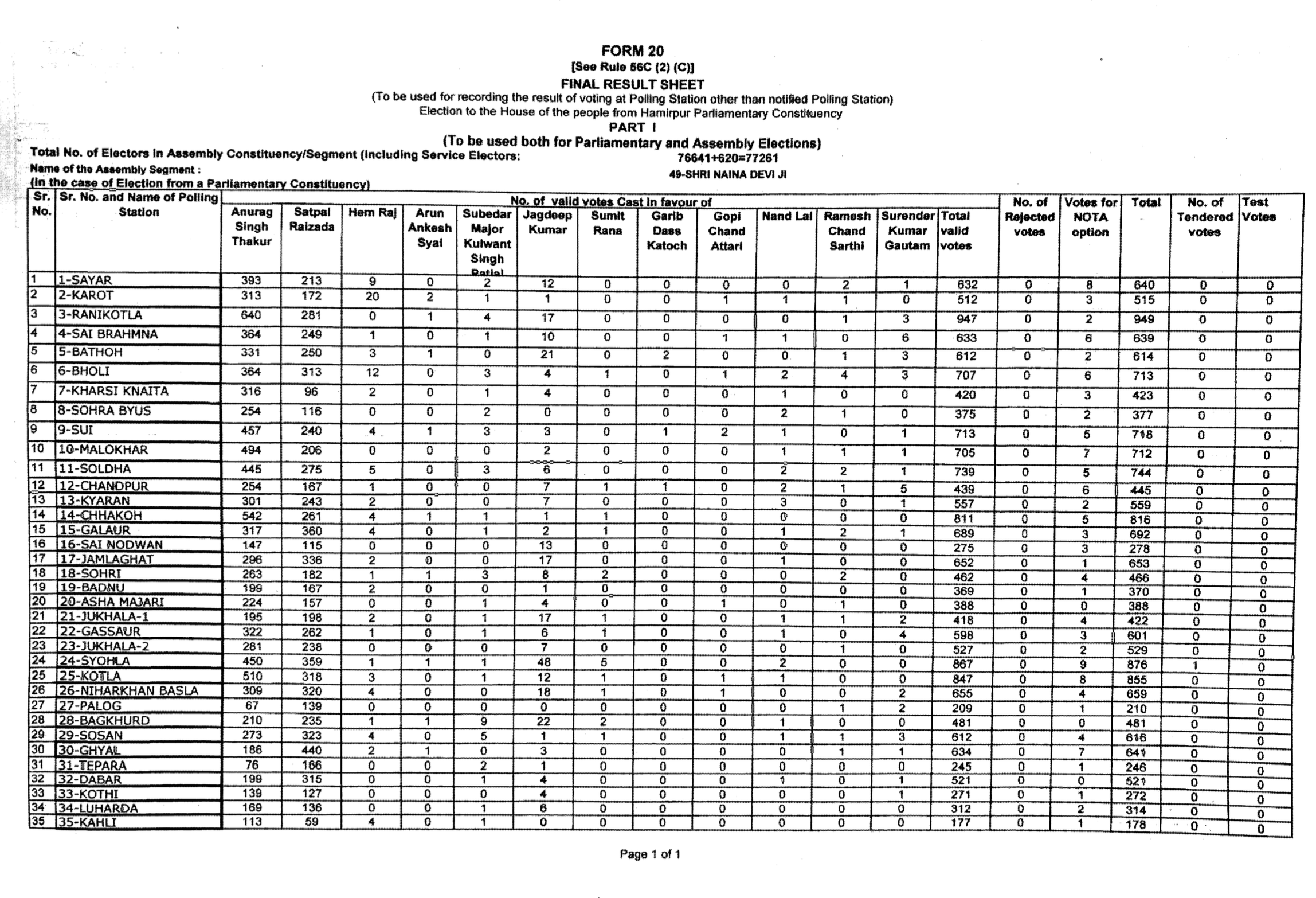
We're just going to use this one page from our previous work replacing OCR with multimodal LLMs:
This is the electoral table we're testing on:
This prompt is used to extract the table:
Convert the first table in this image ${imagePath} into a 2d array. Feel free to ignore formatting fluff or random things. Keep the headers. The number of columns and rows should match - there are no merged columns.
Unfortunately we can only use gemini-flash (both 001 and 002 work as of the writing of this post). We press on!
Approach
The approach was simple but took an hour or two to get working. The idea is to force JSON through a typespec, and visualize the output.
This script was used to get the output (there's a half useful vertex adapter in there as well):
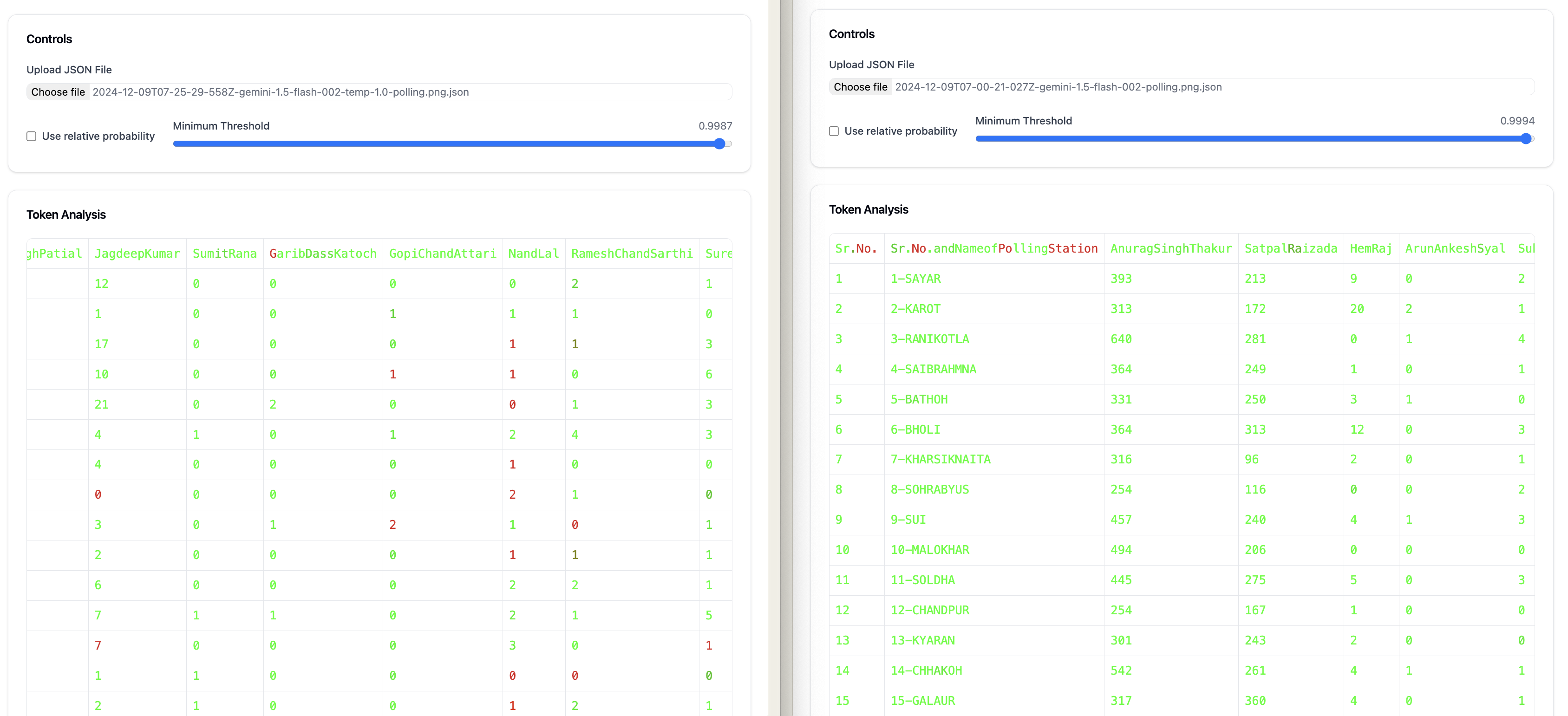
We get this output for our image (at temp 0 with 002):
2024-12-09T07-00-21-027Z-gemini-1.5-flash-002-polling.png.json
{kind=link}
This is the output for 002 at temp 1.0:
2024-12-09T07-25-29-558Z-gemini-1.5-flash-002-temp-1.0-polling.png.json
{kind=link}
This is the output for flash 001:
2024-12-09T07-26-18-299Z-gemini-1.5-flash-001-polling.png.json
{kind=link}
Results
We created this app (with Sonnet and o1):
https://ocr-with-logprobs.vercel.app/
Visualization
What's immediately obvious is that differences are easier to see at higher temp.
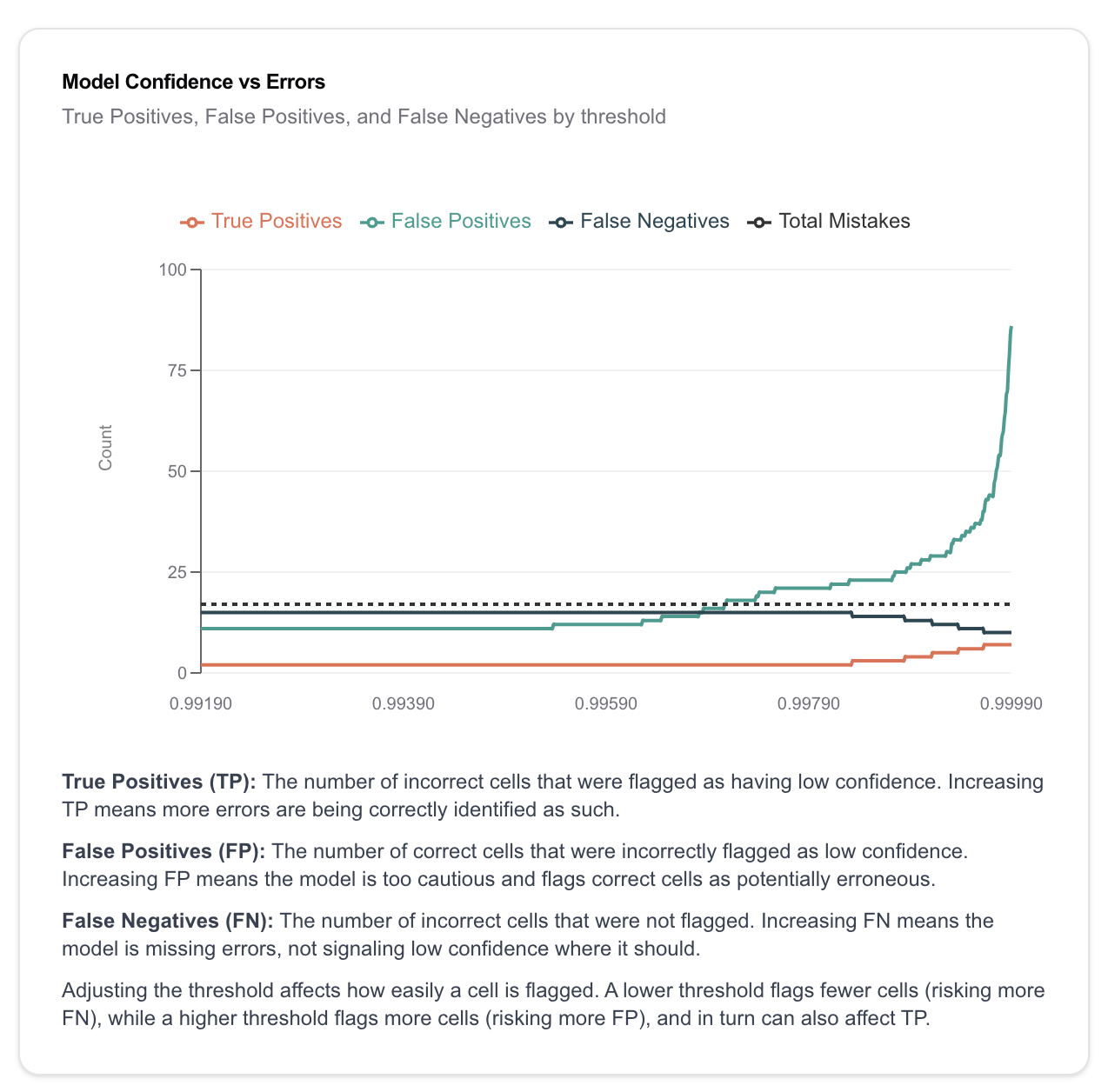
Graphing for positives and negatives using master data:
We can see how we did - not very good!
High temp causes significantly fewer errors, so there's less to go by:
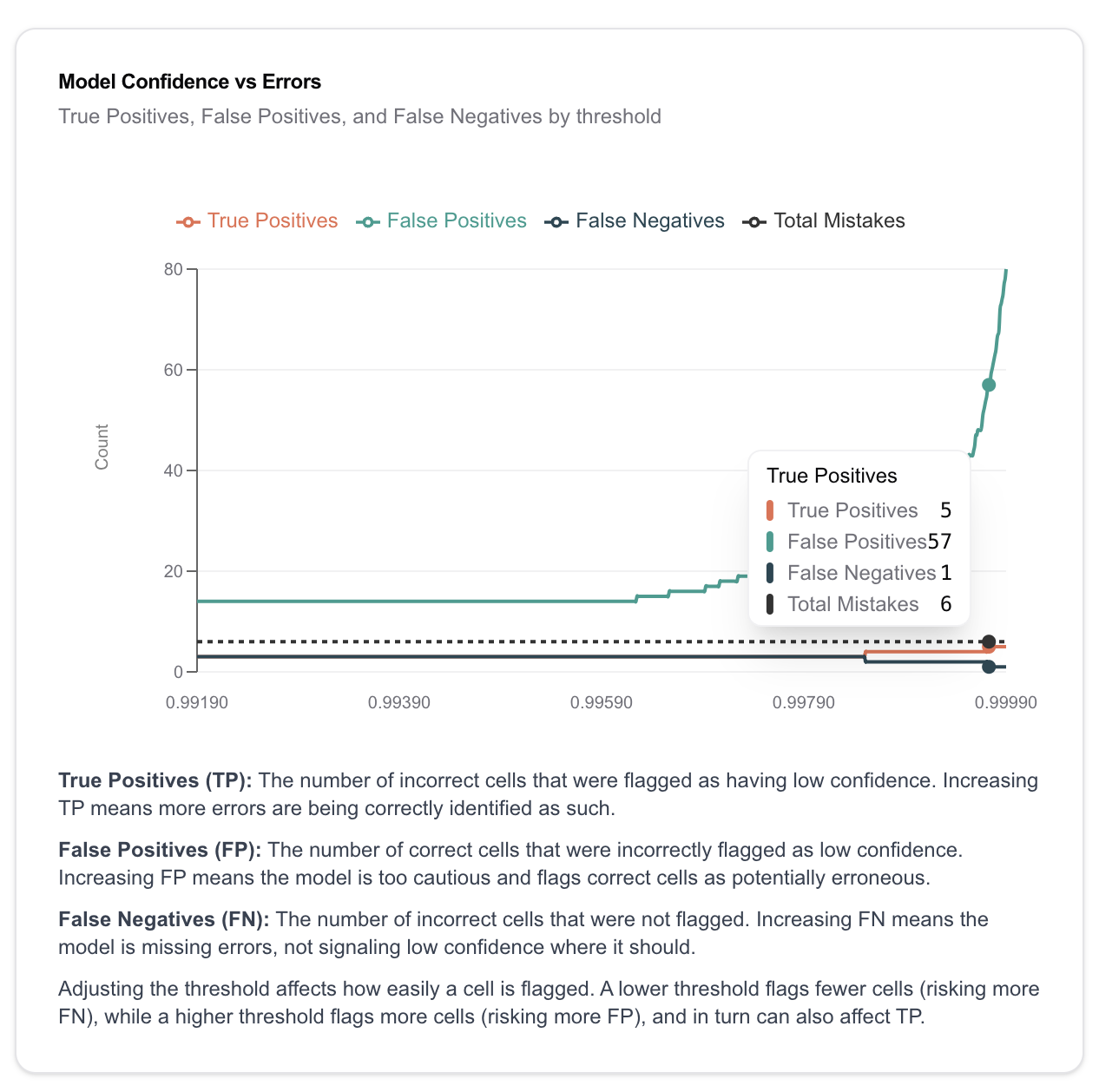
There's not an easy threshold to set to catch mistakes that doesn't raise the false positives by a lot.
Comparing to GPT-4o
Interestingly, OpenAI offers the same thing. Comparing to gpt-4o, we find that the same relationships do not hold.
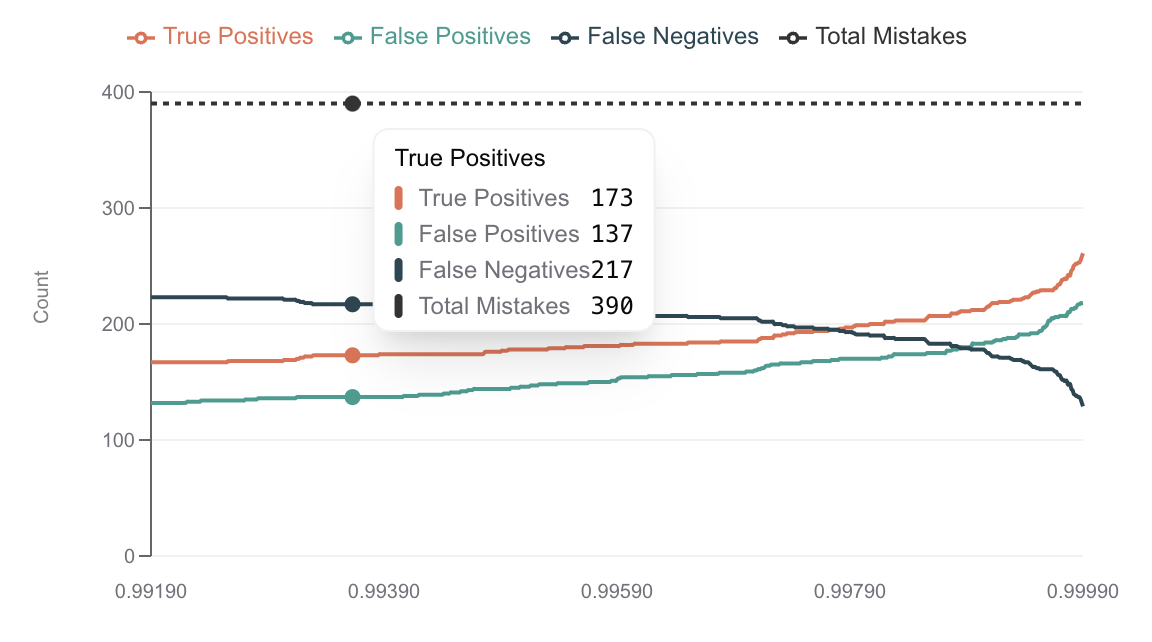
First, high temp is markedly worse than low temp:
High temp
Low temp
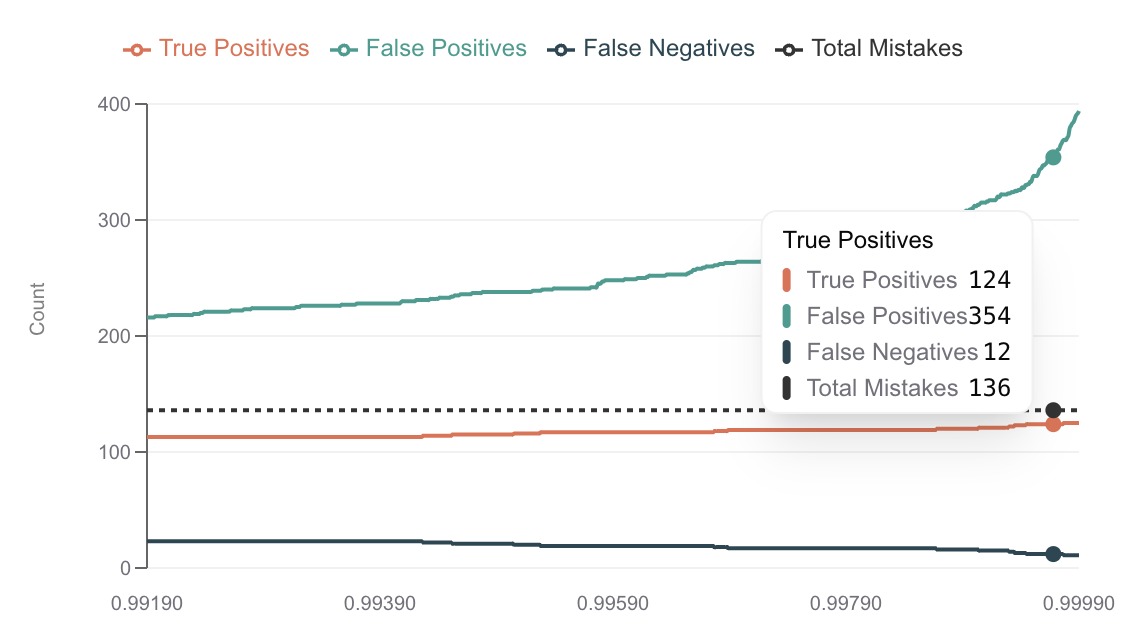
Low temp causes way fewer errors, and our method of using logprobs is significant enough to catch most errors even at very low thresholds.
This needs more study, to determine if this is a model-based difference, somewhat dependent on the dataset, or it's just that gemini had significantly fewer errors to begin with.
For reference, this is what 4o looks like in the dataset:
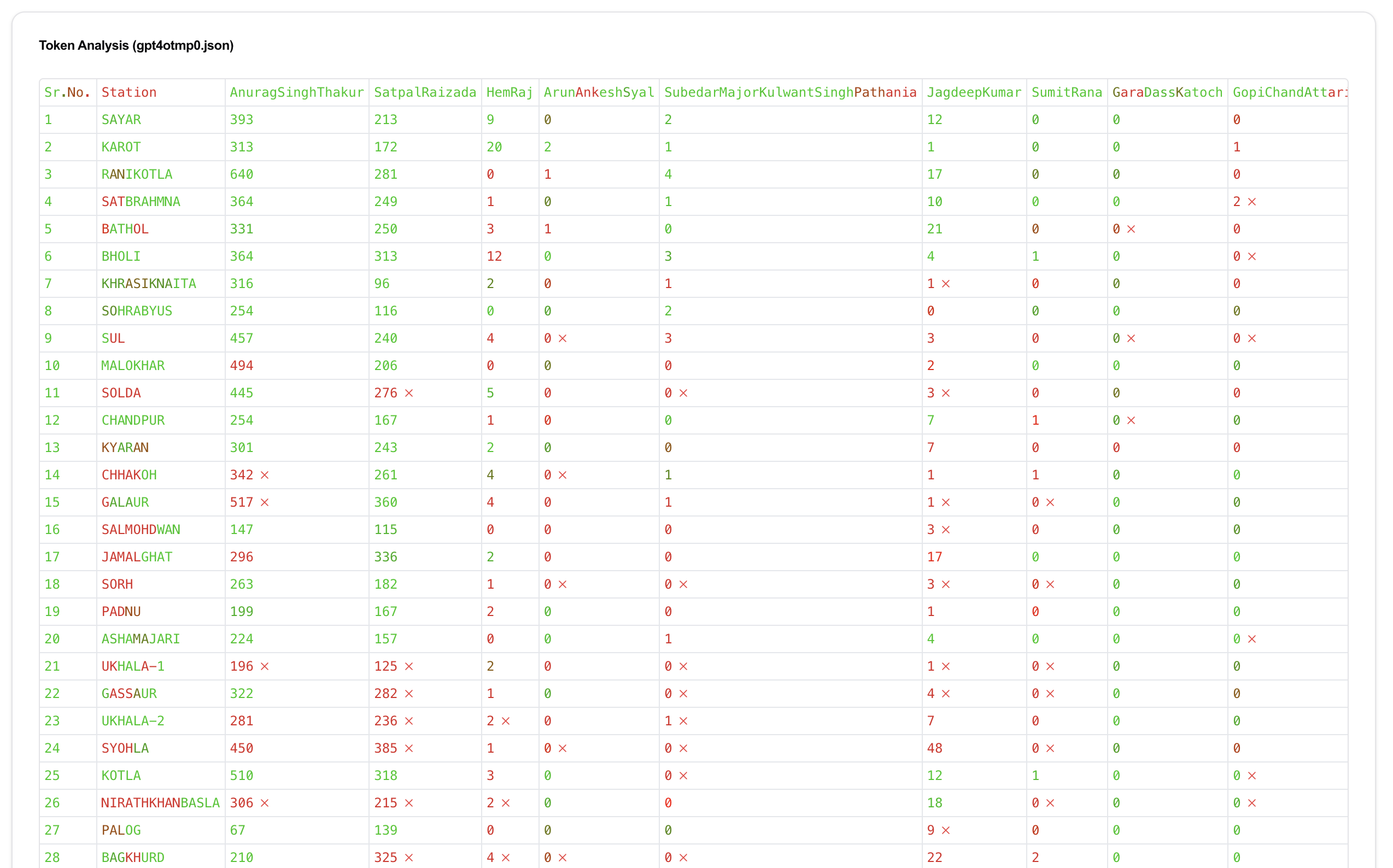
Just look at that sea of red.
Try it yourself
If you'd like to try, go here: https://ocr-with-logprobs.vercel.app/ and load your own dataset, or click on Load CMS Dataset.